
When configuring a pool of NTP servers on a F5 BIG-IP load balancer you need to choose how to check if they are still up and running. There is no specific NTP monitor on a F5 BIG-IP that does an application layer health check (like there is for http or radius). The out-of-the-box options that can be used are only ICMP and UDP monitoring. Let’s first look at the pros and cons of using either (or both) of these monitors. Then let’s build a custom UDP monitor that does a better job at checking whether the NTP servers are still healthy.
ICMP Monitoring
When configuring an ICMP monitor on a pool, the availability of each pool member will be tested by sending an ICMP echo request, expecting an ICMP echo response back. This way, the availability of the pool member is determined by whether the IP stack is reachable.

While this type of monitor is easy to configure, it has some drawbacks:
- ICMP needs to be allowed on the path between the F5 BIG-IP load balancer and the NTP servers, and
- this monitor does not check whether there is a NTP daemon listening on the NTP server.

UDP Monitoring
When configuring a UDP monitor on a pool, the availability of each pool member will be tested by sending a UDP packet to the pool member. Then one of three things can happen:
- There is a response back from the server.
If this happens, the pool member is declared up. - There is an ICMP port unreachable response.
If this happens, the pool member is declared down. - There is no response.
If this happens, the pool member will be declared up as long as no ICMP port unreachable messages are received.

When sending a (non-ntp) UDP packet to an NTP server, there will be no response, so the pool member will always be up, unless there is an ICMP port unreachable response.
This has the following drawbacks:
- The NTP server needs to be configured to send ICMP port unreachable messages when a packet is sent to a port on which there is no daemon listening
- ICMP port unreachable messages need to be allowed on the path between the NTP servers and the F5 BIG-IP load balancer
- When the whole server is down, the UDP dissector won’t detect this.
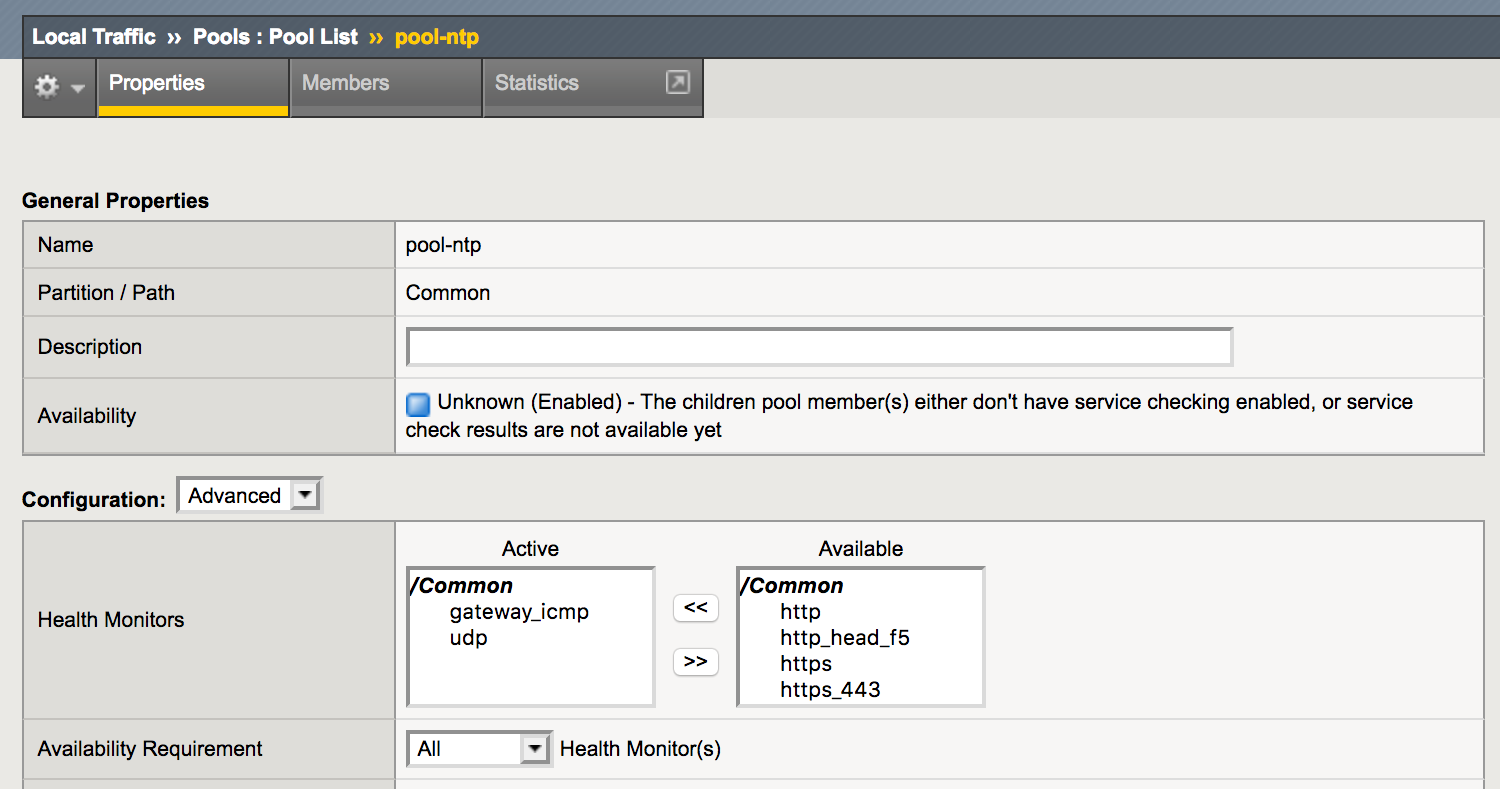
Attaching both the ICMP and the UDP monitor to the pool solves some of the issues, but will not prove whether there actually is a correctly working NTP daemon active on the pool member.
Using an External Monitor
There is the option on F5 BIG-IP load balancers to use a custom script as a health monitor. For testing NTP servers a perl script could be written that sends an NTP request to the NTP server and verifies the NTP response that the NTP sends back. An example on writing such an external monitor can be found at https://devcentral.f5.com/codeshare?sid=411.
While this would be a viable solution, it also has its drawbacks:
- There is a dependency on an external script. It needs to be written and maintained (as it might stop working with an update of the F5 BIG-IP software). Usually the F5 BIG-IP load balancers are under the responsibility of networking people who might not be as confident in maintaining such a script.
- As the monitor is executed on the management plane of the F5 BIG-IP load balancer instead of it’s TMM subsystem, there is a CPU penalty on running external monitors. By default the management plane does not get a lot of resources to work with. While this might not be a real problem when there are just a few servers to check, this can become a problem when there are a lot of pools and/or servers that need to be checked.
Building a Custom UDP Monitor
As it is possible to configure the UDP monitor with a custom string to send to the pool member and then expect a custom string back, it might be possible to create a custom UDP monitor to test whether there is an active NTP daemon listening on the pool member.
Choosing what to send
Let’s start with looking at a NTP request and response in Wireshark


The NTP request is a sequence of binary bytes. As it turns out, it is possible to send a binary sequence in a custom monitor (see: https://devcentral.f5.com/questions/tcp-monitor-with-sending-byte-sequence).
Copying the NTP packet as a hex stream results in:
|
1 |
e30003fa000100000001000000000000000000000000000000000000000000000000000000000000dfb3b34829fc2a88 |
This byte sequence can be sent to a server with ‘nc’ to test whether the server will respond:
|
1 |
echo "e30003fa000000000000000000000000000000000000000000000000000000000000000000000000dfb3b34829fc2a88" | xxd -r -p | nc -u 10.10.0.4 123 |
After executing this command, the NTP server sent a proper NTP response.
Converting this byte sequence to a string that can be used as send string in the custom UDP monitor results in:
|
1 |
\xe3\x00\x03\xfa\x00\x01\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00%NTPMON% |
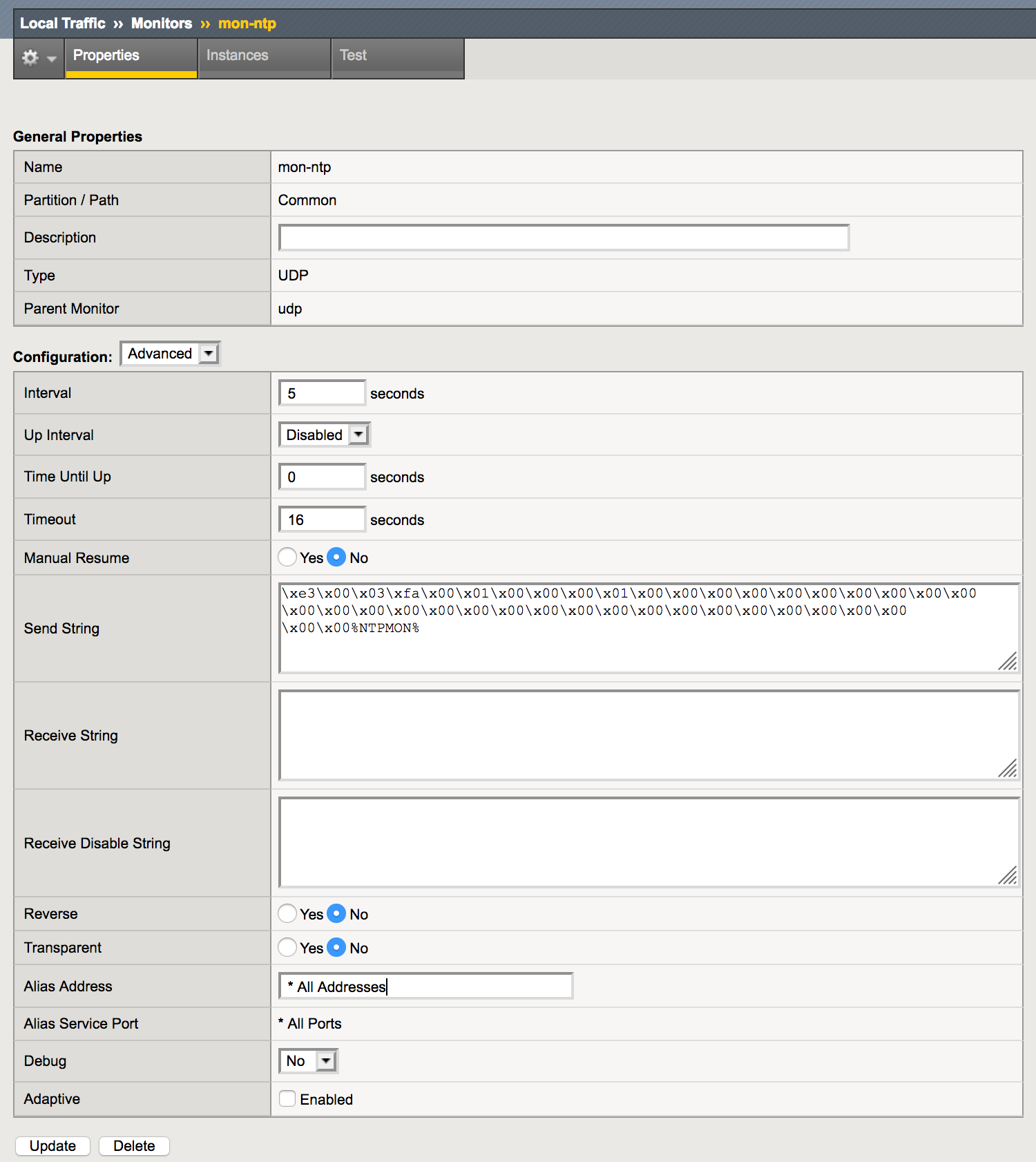
Please note that the “Transmit Timestamp” in this packet has been changed to the string “%NTPMON% to make it easy to recognize these health checks. This results in the timestamp “Dec 8, 2055 08:54:40.301991352 UTC” which did not cause a problem on the NTP servers used during these tests.


Checking the response
Even though there is now a response from the NTP server, it will not solve anything unless the response can be properly checked.
As the “Transmit Timestamp” from the NTP request will always be copied into the “Origin Timestamp” in the NTP response, testing for this timestamp is a great way to check whether there is a working NTP daemon listening on the pool member.
The UDP monitor needs to check whether the “Origin Timestamp” (8 bytes at position 24) of the NTP response are identical to the “Transmit Timestamp” (8 bytes at position 40) of the NTP request. As the string “%NTPMON%” is used as the “Transmit Timestamp”, this string can be checked in the response. The receive string that can be used is:
|
1 |
^.{24}%NTPMON%.{16}$ |
This string skips the first 24 bytes of the response, then checks whether the following 8 bytes contain the string “%NTPMON%” and finally checks whether there are exactly 16 more bytes in the response.

Using this custom monitor will stop the need of adding an ICMP health check to test whether the system is still up and adds a (partial) application level NTP check to the pool member.
Taking it one step further
Even though the NTP response looks like a proper response to the NTP request, it is not clear whether the NTP daemon is (still) properly synchronized to its time sources. It would be nice if this can be checked too.
The NTP protocol uses a stratum value to measure the (network) distance a server has to its reference clock. When the NTP server is not yet synchronized to its reference clock (anymore), a stratum of 0 is returned in the response. So checking for a stratum 0 response would do the trick. Unfortunately a server will not revert to a stratum of 0 when it looses connectivity to its reference clock (after it was successfully synchronized before).
To work around this, the NTP server can be configured with its own clock as a backup time source. It needs to use a very low stratum (like 10) so that the local clock will never be used unless all other timesources are unreachable. When the local backup has been configured, the NTP server will start responding with the configured low stratum whenever all of its reference clocks are unreachable.
The resulting receive string for the UDP monitor will then become:
|
1 |
^.[\x01-\x09].{22}%NTPMON%.{16}$ |
This receive string checks the second byte of the response (which is the stratum value) for a value between 1 and 9 and then checks the rest of the response just like the other receive string.

Wrapping up
On a F5 BIG-IP load balancer it is perfectly possible to check the health and synchronization status of NTP servers in a server pool by:
- configuring a specially crafted byte sequence as the send string in a udp monitor
- and configuring a specially crafted byte sequence as the receive string.
About Sake Blok
This guest blog post was written by Sake Blok. At his company SYN-bit, Sake analyzes and solves Application and Networking problems for its customers. He is also a member of the Wireshark core developer team. Sake has worked a lot with F5 BIG-IP load balancers in the past.
Featured image “Blood pressure measuring. Doctor and patient. Health care.” by agilemktg1 is licensed under Public Domain Mark 1.0.
Thanks for providing this article to build a custom UDP monitor to check the health of NTP servers.
You’re welcome, I’m glad it was useful to you.
Really nice job on your tutorial! I work in DNS and was surprised the F5 didn’t support an NTP health check. Used your custom UDP example and it worked perfectly.
I’ve shared your tutorial with some other engineers.