
What failover times do you expect from a network security device that claims to have high availability? 1 ms? Or at least <1 second? Not so for a fully featured Infoblox HA cluster which takes about 1-2 minutes, depending on its configuration. Yep. “Works as designed”. Ouch. Some details:
Our Setup and Tests
We are using an Infoblox Trinzic 1425 HA cluster at the customer’s site. Beside the NIOS, Grid, and DNSone DNS + DHCP licenses we are using Threat Analytics as well as ActiveTrust RPZ feeds. [Refer to my Infoblox Features & Licenses Naming Clarity post.] After everything was up and running we made a couple of HA failover tests, either via Control -> Force HA Failover as well as via power outage on the active member, and were totally shocked by the failover times of about 1 minute!!!
Even Cricket Liu himself was irritated:
Hmm. Sounds like BIND doesn't start responding again until it's successfully loaded the RPZs (which makes a certain amount of sense, since you'd want your complete resolution policy in place before you started resolving again). But that does sound like a long time.
— Cricket Liu (@cricketondns) February 27, 2019
How could this happen? It turned out that the mere VRRP needs about 3-5 seconds which is kind of expected (though not optimal compared to common firewall failover times from < 1 second). The problem was our intended usage of RPZs with about 9.6 million entries. (The official limit for the Trinzic 1425 hardware is “17,500,000 records at a 50% of max supported DNS rate”, refer to the Infoblox Cloud Services Portal.) It turned out that the RPZs load their content *after* the passive device gets active (and not *before*), while for security reasons the overall DNS service starts responding only after the RPZs are loaded completely. Hence the question: Why isn’t Infoblox loading the RPZs entries *before* an HA event? Wo don’t know.

We always tested with the dnsping tool out of the DNSDiag suite. This tool sends a DNS query per second – nice! Additionally we pinged our VIP to look for the VRRP produced timeout. Everything wrapped up in a screen session split into multiple frames. This is what a failover without any RPZ entries looked like: Total timeout of about 10 seconds – for the ICMP echo-request (at the bottom right) as well as for DNS (5x timeout lines due to 2 s wait for a reply):
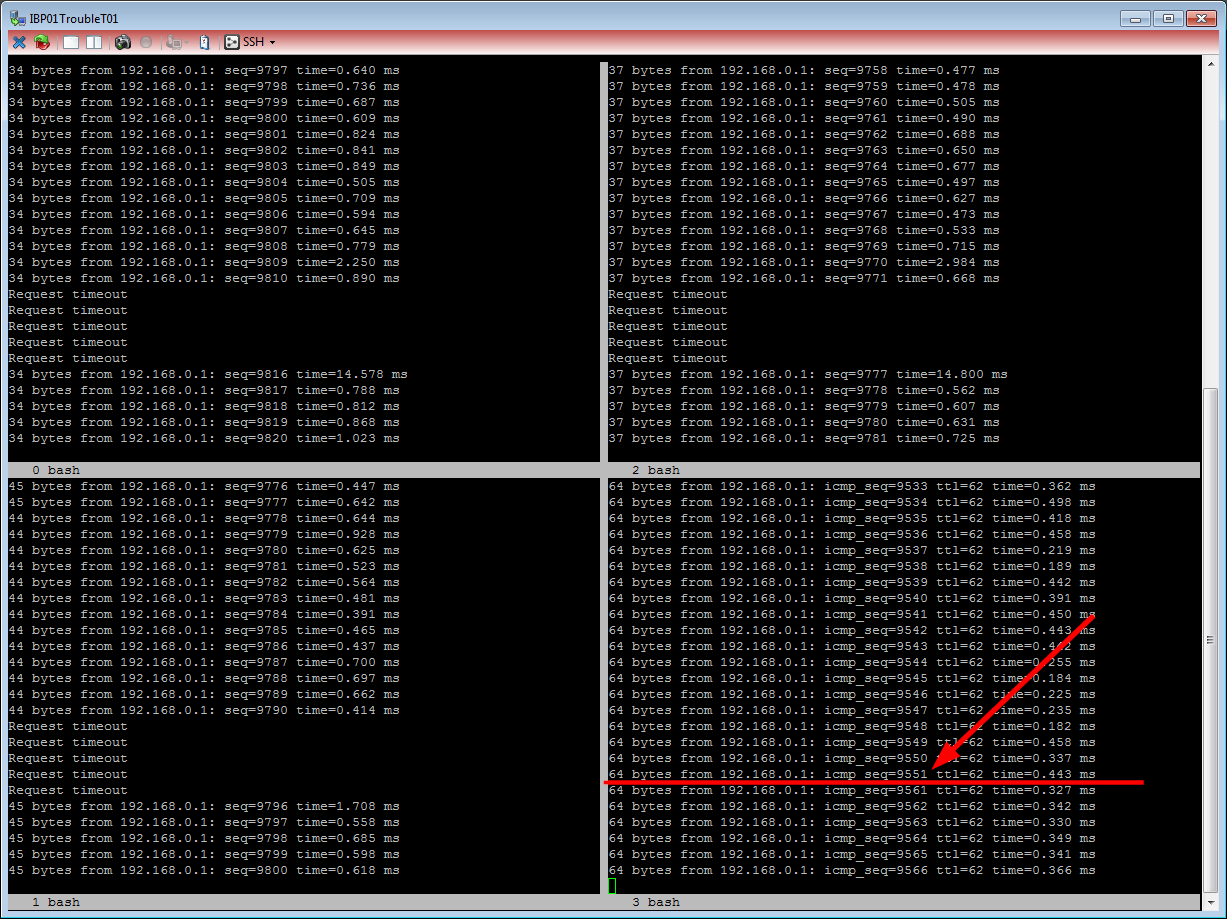
Now this is what it looked like with about 10 million RPZ entries: While the ICMP echo-request (right-hand side) lost 6 pings, the dnsping did not return until more than 1 minute:
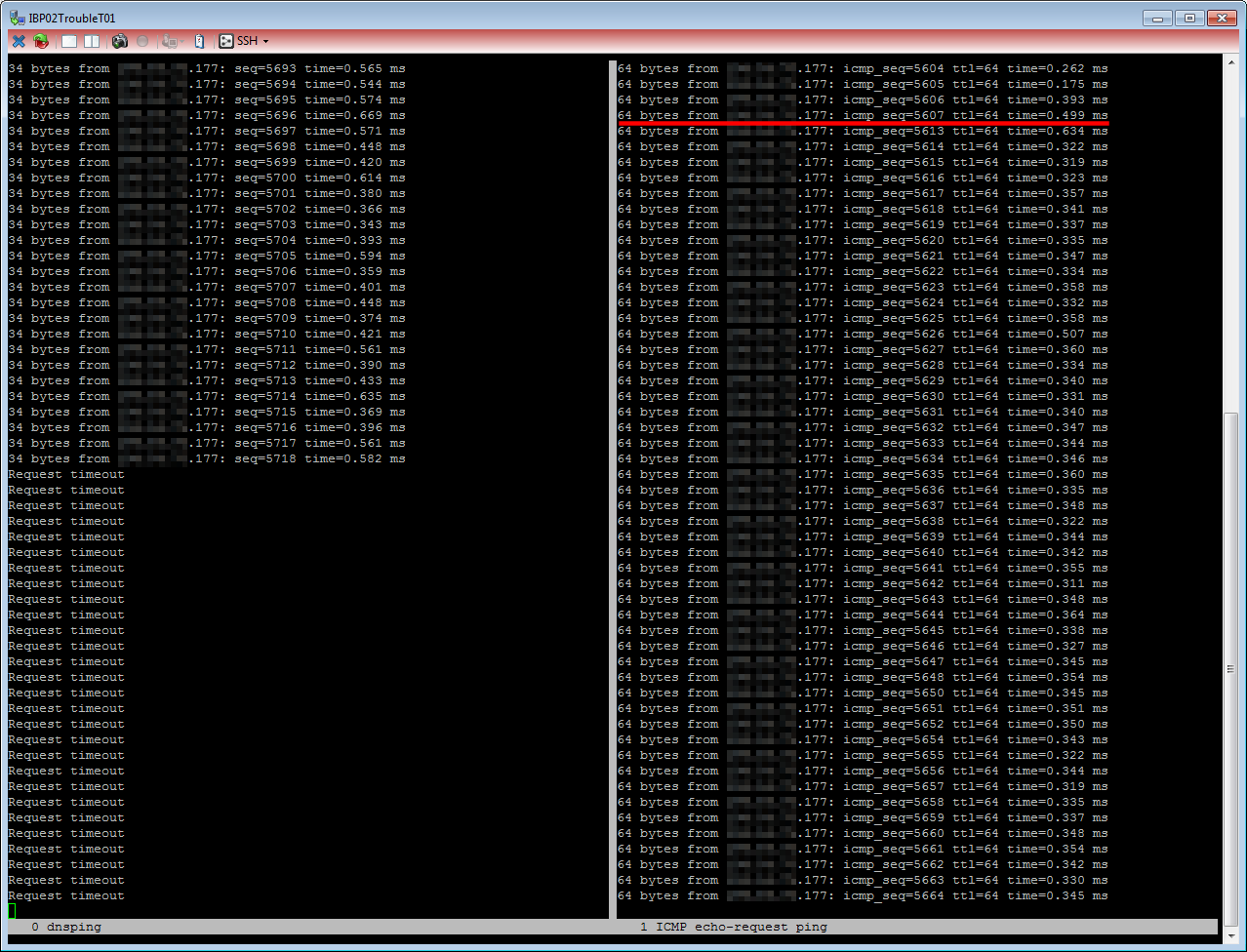
Different RPZ Sizes
We tested five different RPZ sizes. The failover times were quite linear with a max at 1:46 minutes for 17 million entries:
Tested NIOS Versions
We also tested different versions of NIOS. (Took us hours and hours to down- ‘n upgrade the whole Grid in several directions.)
- 8.2.6
- 8.3.2
- 8.3.3
- 8.4.0-EA
The failover time was almost exactly the same on all tested version. ;(
Conclusion
In general I really like the Infoblox DDI appliances. Everything works quite good, it is well designed and feature complete. However, this de facto not reliable HA is a hard one. :( No single sentence about this in any documentation, online resources, official trainings… Gaining trust looks different.
Finally I want to say that I have made some really good experiences with Infoblox as well. Such as this one:
Wow, I just got a personal mail from an @Infoblox SE that they have fixed this issue I posted on Twitter last year. (NIOS 8.3.3) This is awesome. Way better than other security companies that do not care about my feature requests at all. Thanks @cricketondns et al.! https://t.co/ICkWGRLvwJ
— Johannes Weber ? (@webernetz) February 14, 2019
Hence I am looking forward to their solutions concerning this HA behaviour.
Featured image “FAIL” by z Q is licensed under CC BY-NC-ND 2.0.