
I built a basic test laboratory with a Palo Alto Networks PA-200 firewall and two Cisco Catalyst 2950 switches in order to test the Spanning Tree Protocol (STP) for achieving Layer 2 redundancy for the physical connections to/from the firewall. This post lists the configurations, “show spanning-tree” outputs from the switches and a few other outputs after several tests. Not all tests ran without any problems so I think there must be something wrong with my configurations, the test sequences, with the STP process, or with the MAC address tables. Maybe some readers have similar experiences?
[UPDATE] Problem solved! I missed the layer 2 zones. Description at the bottom. [/UPDATE]Though the Palo Alto firewall does not participate in STP itself, it forwards the BPDUs from the switches. That is: The complete STP process takes place at the two switches while the firewall is a simple Layer 2 forwarding device. All ports between the network devices are configured as VLAN trunk ports. I am not using the firewall as a “Layer 2 firewall” with appropriate zones, but as a Layer 3 firewall with VLAN interfaces. That is: There are no policies between the layer 2 interfaces during the tests.

Here is the basic laboratory installation:

The Cisco Catalyst 2950 switch runs with IOS “12.1(22)EA14” while the PA-200 has PAN-OS 5.0.8 installed. The two notebooks are simple Linux machines.
Layer 2 Configuration PA-200
The following screenshots show the configuration on the Palo Alto firewall. The two physical interfaces (Layer2) have two subinterfaces with the VLANs 120 and 125 configured. Two VLAN-Interfaces (Layer3) provide routing and are configured with Layer3 Zones. Finally, the two VLANs have the subinterfaces and the VLAN interfaces assigned to it.

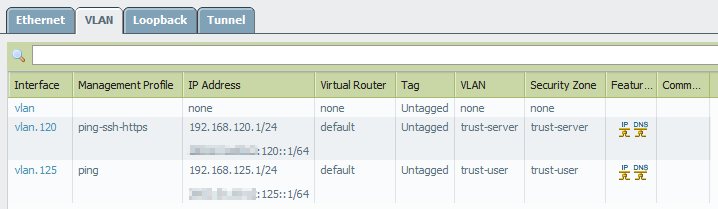

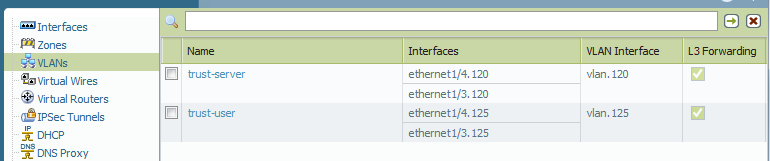
Switch Configuration with STP
The following listing shows the relevant Cisco commands in the test lab. SW01 is listed, while SW02 is exactly the same except the management IPv4 address. Note that I have only configured the first two spanning-tree commands while the other two appeared automatically.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
! spanning-tree mode rapid-pvst spanning-tree portfast default no spanning-tree optimize bpdu transmission spanning-tree extend system-id ! ! ! ! interface FastEthernet0/1 description PA-200 eth1/3 switchport mode trunk ! ! interface GigabitEthernet0/1 description Crosslink zu fd-wv-sw02 switchport mode trunk ! interface Vlan120 ip address 192.168.120.5 255.255.255.0 no ip route-cache ! ip default-gateway 192.168.120.1 ! |
Expected Test Results
Since the Layer 2 interfaces on the Palo Alto behave like a normal switch with no STP enabled, the whole spanning tree process should work as normal from the perspective of two Cisco switches. That is: In the case of a loop (all cables are plugged in) one port of the switch should be in blocked (BLK) mode while the other should still forward (FWD) any traffic. However, the Palo Alto firewall should recognize the change of MAC addresses from one physical port to another. This should be seen in the MAC address table. The same is expected for the CAM tables of the switches.
Test Sequence & Results
I created the following test sequence and captured the “show spanning-tree” output from both switches after each test. Beginning with test #11 I also captured the contents of the MAC address tables and the ARP caches of both switches and the firewall.
I pinged an external IPv4 address from an internal client that resided behind SW02. Beginning with test #11 I pinged the default gateway, i.e., the Palo Alto address, in the vlan 125 from both notebooks that are shown in the figure above.
- Only cable from PA-200 to SW01 was plugged in.
- Both cables were plugged in.
- Cable to SW01 was ripped off. 8 ping timeouts.
- Both cables were plugged in. 7 ping timeouts, then traffic ok. BUT: Both switches are not accessible via ssh anymore. After doing a console connection to one of the switches and a ping to the other switch, the vty connections worked again. (???)
- Port fa0/1 on SW02 was “shutdown”.
- “no shutdown”.
- Port fa0/1 on SW01 was “shutdown”. 7 ping timeouts. BUT: ssh connection to both switches lost one more time. No further tests.
- “no shutdown”. 7 ping timeouts. Still both ssh connections to the switches were gone. No new connections were possible. (The ping to the Internet still worked!) Tried to reload SW02. But still no ssh connection possible. (???) Port fa0/1 from SW01 ripped off. 8 ping timeouts. NOW both switches are accessible via ssh again.
- Port plugged in again. 6 ping timeouts. Both switches are NOT accessible via ssh. (???)
- Plugged off the power supply from both switches and plugged them in again. Now both switches are accessible via ssh again.
- Setup for a new scenario: Both notebooks are on port fa0/8 of the appropriate switches. Notebook nb02 was pinging nb01.
- Cut cable between both switches (gi0/1). Ping from nb02 to nb01 did not work anymore.
- Palo Alto: “clear mac trust-server”. Ping from nb02 to nb01 still did not work.
- Cable between both switches plugged in again. Ping from nb02 to nb01 worked directly! (<- this is strange!)
- Last scenario: Both notebooks pinging the default gateway, i.e., the VLAN interface of the Palo Alto firewall.
- Cut cable between both switches (gi0/1). Ping from nb01 to the gateway still OK, and the ping from nb02 to the gateway timed out but came back after a while. However, the ping from nb02 to nb01 did not work anymore! (???)
- Cable plugged in again. Ping from nb02 to nb01 worked directly. After a while, the ping from nb02 to the gateway came back again, too.
The following MAC address were used in this laboratory:
|
1 2 3 4 5 |
nb01 (plugged into sw01) 00:1d:92:53:58:12 nb02 (plugged into sw02) 00:21:9b:cc:ab:07 PA vlan b4:0c:25:05:8e:01 sw01 00:0a:8a:a1:5a:80 sw02 00:0a:b7:18:d6:00 |
As an example here are the two “show spanning-tree” outputs from VLAN120 for both switches after the test #2 case in which all cables are plugged in. It basically shows that the second switch put the Fa0/1 port into “Altn BLK” mode. (Since there were some other access ports plugged in, the interface list with “Edge P2p” entries differ.)
SW01:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
fd-wv-sw01#show spanning-tree VLAN0120 Spanning tree enabled protocol rstp Root ID Priority 32888 Address 000a.8aa1.5a80 This bridge is the root Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec Bridge ID Priority 32888 (priority 32768 sys-id-ext 120) Address 000a.8aa1.5a80 Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec Aging Time 300 Interface Role Sts Cost Prio.Nbr Type ---------------- ---- --- --------- -------- -------------------------------- Fa0/1 Desg FWD 19 128.1 P2p Fa0/4 Desg FWD 19 128.4 Edge P2p Fa0/8 Desg FWD 19 128.8 Edge P2p Fa0/10 Desg FWD 19 128.10 Edge P2p Gi0/1 Desg FWD 4 128.25 P2p |
SW02:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
fd-wv-sw02#show spanning-tree VLAN0120 Spanning tree enabled protocol rstp Root ID Priority 32888 Address 000a.8aa1.5a80 Cost 4 Port 25 (GigabitEthernet0/1) Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec Bridge ID Priority 32888 (priority 32768 sys-id-ext 120) Address 000a.b718.d600 Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec Aging Time 300 Interface Role Sts Cost Prio.Nbr Type ---------------- ---- --- --------- -------- -------------------------------- Fa0/1 Altn BLK 19 128.1 P2p Gi0/1 Root FWD 4 128.25 P2p |
Here are the listings after test #16 in which the ping from nb02 to nb01 did not work:
Palo Alto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
weberjoh@fd-wv-fw02> show arp all maximum of entries supported : 500 default timeout: 1800 seconds total ARP entries in table : 8 total ARP entries shown : 8 status: s - static, c - complete, e - expiring, i - incomplete interface ip address hw address port status ttl -------------------------------------------------------------------------------- ethernet1/1 172.16.1.1 b0:c6:9a:fd:ca:8a ethernet1/1 c 736 vlan.120 192.168.120.2 b4:0c:25:05:8e:00 ethernet1/3 c 1540 vlan.120 192.168.120.5 00:0a:8a:a1:5a:80 ethernet1/3 c 919 vlan.120 192.168.120.6 00:0a:b7:18:d6:00 ethernet1/3 c 826 vlan.120 192.168.120.10 00:1d:92:53:58:12 ethernet1/3 c 1472 vlan.120 192.168.120.11 00:21:9b:cc:ab:07 ethernet1/4 c 1744 vlan.125 192.168.125.33 14:fe:b5:b2:3f:e8 ethernet1/4 c 1795 vlan.125 192.168.125.35 3c:97:0e:62:07:5f ethernet1/4 c 1795 weberjoh@fd-wv-fw02> show mac trust-server maximum of entries supported : 500 default timeout : 1800 seconds total MAC entries in table : 7 total MAC entries shown : 7 status: s - static, c - complete, i - incomplete vlan hw address interface status ttl -------------------------------------------------------------------------------- trust-server 00:1d:92:53:58:12 ethernet1/3.120 c 944 trust-server 00:0a:8a:a1:5a:80 ethernet1/3.120 c 917 trust-server 00:0a:8a:a1:5a:81 ethernet1/3.120 c 823 trust-server b4:0c:25:05:8e:00 ethernet1/3.120 c 1239 trust-server 00:21:9b:cc:ab:07 ethernet1/4.120 c 824 trust-server 00:0a:b7:18:d6:00 ethernet1/3.120 c 824 trust-server 00:0a:b7:18:d6:01 ethernet1/4.120 c 1710 |
SW01:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
fd-wv-sw01#show mac-address-table Mac Address Table ------------------------------------------- Vlan Mac Address Type Ports ---- ----------- -------- ----- All 000a.8aa1.5a80 STATIC CPU All 0100.0ccc.cccc STATIC CPU All 0100.0ccc.cccd STATIC CPU All 0100.0cdd.dddd STATIC CPU 120 000a.b718.d601 DYNAMIC Fa0/1 120 001d.9253.5812 DYNAMIC Fa0/8 120 b40c.2505.8e00 DYNAMIC Fa0/4 120 b40c.2505.8e01 DYNAMIC Fa0/1 1 b40c.2505.8e01 DYNAMIC Fa0/1 125 000a.b718.d601 DYNAMIC Fa0/1 125 14fe.b5b2.3fe8 DYNAMIC Fa0/1 125 b40c.2505.8e01 DYNAMIC Fa0/1 Total Mac Addresses for this criterion: 12 fd-wv-sw01#show arp Protocol Address Age (min) Hardware Addr Type Interface Internet 192.168.120.1 0 b40c.2505.8e01 ARPA Vlan120 Internet 192.168.120.5 - 000a.8aa1.5a80 ARPA Vlan120 fd-wv-sw01#show spanning-tree vla 120 VLAN0120 Spanning tree enabled protocol rstp Root ID Priority 32888 Address 000a.8aa1.5a80 This bridge is the root Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec Bridge ID Priority 32888 (priority 32768 sys-id-ext 120) Address 000a.8aa1.5a80 Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec Aging Time 300 Interface Role Sts Cost Prio.Nbr Type ---------------- ---- --- --------- -------- -------------------------------- Fa0/1 Desg FWD 19 128.1 P2p Fa0/4 Desg FWD 19 128.4 Edge P2p Fa0/8 Desg FWD 19 128.8 Edge P2p |
SW02:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
fd-wv-sw02#show mac- Mac Address Table ------------------------------------------- Vlan Mac Address Type Ports ---- ----------- -------- ----- All 000a.b718.d600 STATIC CPU All 0100.0ccc.cccc STATIC CPU All 0100.0ccc.cccd STATIC CPU All 0100.0cdd.dddd STATIC CPU 125 000a.8aa1.5a81 DYNAMIC Fa0/1 125 14fe.b5b2.3fe8 DYNAMIC Fa0/15 125 3c97.0e62.075f DYNAMIC Fa0/13 125 b40c.2505.8e01 DYNAMIC Fa0/1 1 b40c.2505.8e01 DYNAMIC Fa0/1 120 000a.8aa1.5a81 DYNAMIC Fa0/1 120 0021.9bcc.ab07 DYNAMIC Fa0/8 120 b40c.2505.8e01 DYNAMIC Fa0/1 Total Mac Addresses for this criterion: 12 fd-wv-sw02#show arp Protocol Address Age (min) Hardware Addr Type Interface Internet 192.168.120.1 0 b40c.2505.8e01 ARPA Vlan120 Internet 192.168.120.6 - 000a.b718.d600 ARPA Vlan120 fd-wv-sw02#show spanning vlan 120 VLAN0120 Spanning tree enabled protocol rstp Root ID Priority 32888 Address 000a.8aa1.5a80 Cost 19 Port 1 (FastEthernet0/1) Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec Bridge ID Priority 32888 (priority 32768 sys-id-ext 120) Address 000a.b718.d600 Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec Aging Time 300 Interface Role Sts Cost Prio.Nbr Type ---------------- ---- --- --------- -------- -------------------------------- Fa0/1 Root FWD 19 128.1 P2p Fa0/8 Desg FWD 19 128.8 Edge P2p |
Summary of the presence of the MAC addresses from nb01 and nb02:
| nb01 | nb02 | |
|---|---|---|
| 15_pa | eth1/3.120 | eth1/3.120 |
| 15_sw01 | Fa0/8 | Gi0/1 |
| 15_sw02 | Gi0/1 | Fa0/8 |
| 16_pa | eth1/3.120 | eth1/4.120 |
| 16_sw01 | Fa0/8 | --> n/a <-- |
| 16_sw02 | --> n/a <-- | Fa0/8 |
–> That is, after test #16 the MAC addresses from both notebooks are NOT PRESENT in the switch’ MAC address table while it should have shown “Fa0/1” because they are accessible through the Palo Alto firewall. However, I do not know why this happens. Maybe the firewall does not forward all Ethernet frames?
In summary I captured many outputs from the two switches and the firewall after each test. If someone is *really* interested in the details, the following zip file contains all outputs. They are counted appropriate to the test case numbers with a suffix of “sw01” and “sw02” for the switches and “pa” for the Palo Alto firewall:
![]()
Conclusion
The basic STP tests showed the expected behaviour. For example, the default gateway was always accessible. The switches correctly recognized the layer 2 loop while they changed the port states to “forward” in the case of a loop-free environment. However, in some situations the switches did not recognize the real exit-interface for some Ethernet frames. At this point I do not know whether this is a configuration mistake by myself or a bug in any of the systems…? If anyone has an idea, please comment it!
Problem Solved!
After some further investigation and discussions with colleagues I understood the problem: At the Palo Alto firewall the Layer2 subinterfaces also need Security Zones (Layer2) and an allow policy in order to allow intra-zone traffic! Since we are talking about a *real* firewall, this makes sense at all. Now the test laboratory worked, especially the cases in which I pinged from nb02 to nb01, even when the cable between both switches is cut.
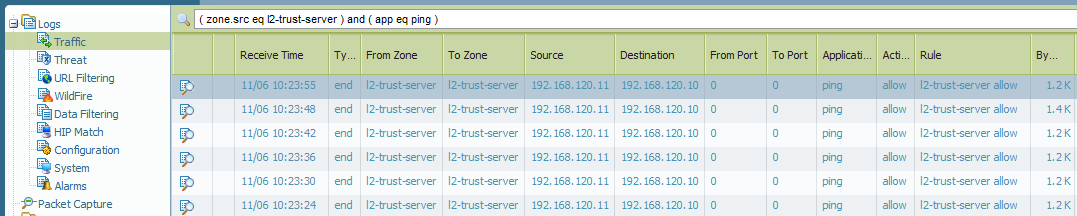
Here are the new screenshots from the Palo Alto firewall with the correct layer 2 security zones, the intra-zone policy and the pings in the traffic log:
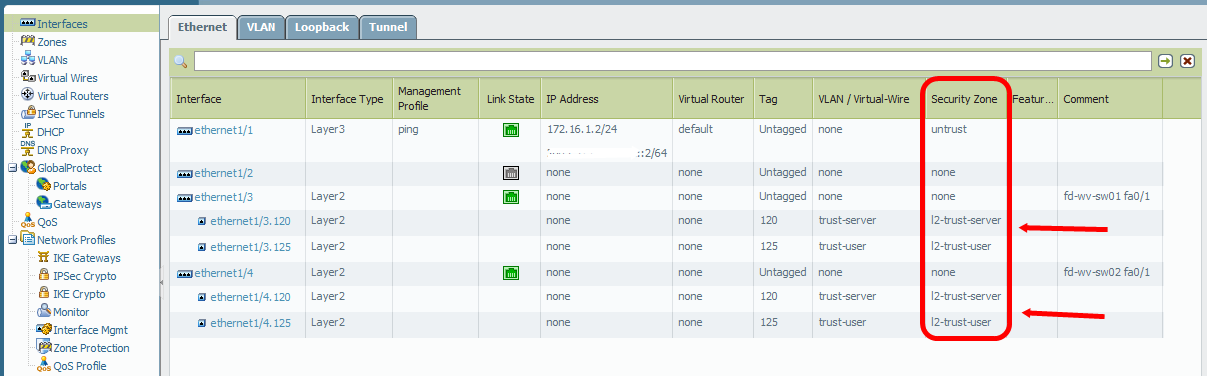
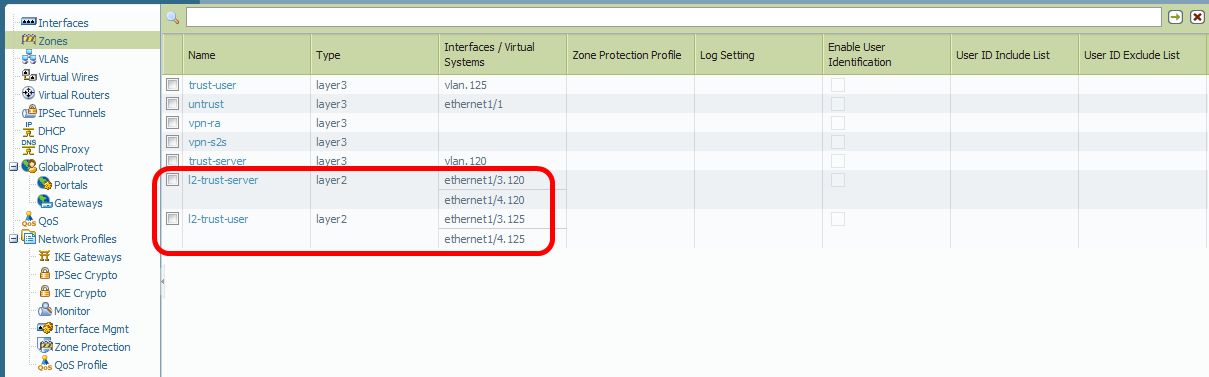
![]()
Further Reading
Some links concerning this article:
- Wikipedia: Spanning Tree Protocol
- Cisco: Understanding and Configuring Spanning Tree Protocol (STP) on Catalyst Switches
- Palo Alto Networks: General Port/Interface Information
- Palo Alto Networks: Layer 2 Networking
Featured image “two Cisco 3750s” by Bob Mical is licensed under CC BY-NC 2.0.
Hi,
Thanks for posting this article. I have built a very similar scenario as a POC for a customer. Things seem to work more or less as expected, however I am seeing 30s outages to traffic while RSTP reconverges. In hunting for answers, I came across your blog…
I am using Meraki MS220 switches, in the same configuration as in your drawings. RSTP should converge much more quickly than I am seeing, so I am wondering if perhaps the PA is causing the delay for some reason…
Were you able to improve on the outage times you observed? I notice you were using rapid PVST, and I assume your 7-8 pings lost equate to the same 30sec I am seeing…
Did you ever put this solution into production? If so, were there any unforeseen issues? I am looking to deploy this setup to 5 international sites, so any reassurances / observations you may have would be appreciated…
Regards,
Tim
Hi Tim,
I have not further tuned the timers for my test lab. In theory, RSTP should converge in a few seconds (and not in 30-50 seconds as STP). Please try your network configuration without the Palo, i.e., plugin the two cables directly into the switches. [Instead of Switch <-> Palo <-> Switch, use Switch <-> Switch]. You should have a loop which is blocked by RSTP. Then try your tests and compare them with the test with the Palo in between. How do the network outages change?
Yes, we are using a similar design at the customer’s site. I know that there was an issue with the ARP caches on the layer 2 interfaces on the Palo that was fixed in 5.0.9 or so (I don’t have any further details here, sorry). I think it is running now without any further problems. But I am not fully involved there…
Thanks for the quick response Johannes.
After I posted, I tried disabling STP on a 3560, and put it in place of the PA. The Meraki switches converged as expected with the triangle topology, discarding on the correct port. They exhibited about the same delay (25 seconds) when I dropped the active uplink to the 3560.
I have confirmed that RSTP converges very quickly when I have the Meraki switches only – ie, loop between two switches.
The convergence delay is the only issue i have noticed with the network, and the customer is more than happy to have that 25s interruption if it means clients on the remaining switches can continue to function if the primary uplink/switch is lost…
Thanks again,
Tim
Hi
I just need a help . as I applied the same topology in my company but we are facing random instability in the network and many times I received in PA logs ” incomplete MAC address ” so is this related to an ARP issue or what ?
Note : the PA version is 6.1.4 the latest version
Hi Tamer,
of course I cannot troubleshoot your issue with these few information. However, “incomplete MAC address” might be the problem when no ARP answer is coming. So yes, this might be related to your layer-2 design. Have you tested some packets “from left to right”, similar to my scenario? Have you the layer-2 policies in place on the Palo? Are you sure that the requested IP address is really alive (that is, it really answers with its MAC address to the ARP request)?
Any need for the rules considering the below?
There are two default rules on the Palo Alto Networks firewall regarding security policies:
Deny cross zone traffic
Allow same zone traffic
The second one (allow same zone traffic) should fit. However, this only works if you DO NOT have an explicit “deny any any” rule before that. ;) Since many IT admins prefer to have an explicit deny any any rule, the final default rules from Palo Alto won’t be hit, because every traffic is already denied.
What does your log say? You should see denied packets, it the security rules are the cause.
Have you tested this on Pan OS 6.1.1? We attempted to replicate your configuration and found that the connection to the second switch does not get blocked with STP. If we connect the two switches together using the same ports, STP blocks the traffic as expected on the duplicate path. (12.2(44)SE5).
No, the last PAN-OS version I had with this setup was 5.0.x. I have not done further tests in the last months about that… I am sorry.
Have you configured the layer2 policies?
Yes, I’ve tried it with and without layer2 policies. A loop is created in both cases. I have a case open with support and they are trying to reproduce it in a lab. Thanks for your response.
We were able to get this working on both 6.1.1 and 7.0.1. Our problem was only looping on vlan.1 which was our tagged default vlan. As soon as we switched our default vlan to untagged the loop went away.
Thanks for the resource and the help.
Just completed the RTSP setup.
Seems RSTP/MST BPDU packets traverse through PA via Native VLAN (1)..
BPDU packets didn’t pass till I added main interfaces on PA to a specific Untagged VLAN:
“1 Native VLAN” {
interface [ ethernet1/3 ethernet1/4];
}