
Angreifer verwenden gern Ping und Traceroute, um Server im Internet ausfindig zu machen. Das bringt viele Security-Admins in Versuchung, den Ping- und Traceroute-Verkehr mittels ihrer Firewall in ihrem Netz zu unterbinden. Doch damit behindern sie nur die Arbeit von Server-Administratoren, denn es gibt noch viel mehr Möglichkeiten, Server aufzuspüren.
Die Kommandozeilen-Tools Ping und Traceroute, die zu jedem modernen PC-Betriebssystem gehören, sind sowohl bei Angreifern als auch bei Server-Administratoren beliebte Werkzeuge – sie lassen sich leicht über Skripte automatisieren und liefern so in kurzer Zeit einfache Antworten auf die Frage: Läuft unter einer bestimmten IP-Adresse ein Server oder nicht? Wenn ja, dann sind Server-Administratoren zufrieden, während Angreifer die Ärmel hochkrempeln, um den Server näher zu untersuchen und möglichst zu übernehmen.
Genau Letzteres wollen Security-Admins unterbinden und manche richten dann eine vermeintliche Totalblockade ein: Sie unterbinden mittels Firewall-Regeln jeglichen Ping- und Traceroute-Verkehr zum und vom Server. Doch das sind Placebo-Regeln – sie beruhigen lediglich, ohne die Sicherheit zu erhöhen und behindern aber das Monitoring des Servers. Denn öffentliche Server lassen sich auch ohne Ping leicht identifizieren.

Dafür gibt es eine Handvoll von Universal- und Spezialwerkzeugen, deren Konzepte und Funktionen wir detailliert vorstellen. Wir stellen Ping und Traceroute an den Anfang, weil sich darüber grundlegende Konzepte am einfachsten erklären lassen. Danach folgen Monitoring-Tools auf Applikationsebene, für die Traceroute mit etwas Know-how ebenfalls nutzbar ist. Alle optionalen Tools finden Sie über ct.de/y8pp.
Ping- und Traceroute-Grundlagen
Der Ping-Befehl ist ein simples Tool, mit dem sich die Netzwerkverbindung zu einem Gerät testen lässt. Die Anfrage des Senders (Echo Request) und die Antwort des Empfängers (Echo Reply) sind in der Protokollspezifikation RFC 792 definiert (Internet Control Message Protocol, ICMP). Wenn der Absender des Ping-Kommandos ein Reply-Paket vom Zielsystem erhält, bedeutet das, dass die Netzwerkstrecke zur angefragten IP-Adresse funktioniert. Zudem liefert Ping die Signallaufzeit für den Hin- und Rückweg. Die Laufzeit (Latenz) ist ein einfaches Maß für die Reaktionsgeschwindigkeit des Servers. Je kürzer die Latenz, desto zufriedener der Admin und die User.
Auf Windows- und Unix-Systemen lautet der Befehl schlicht ping. Darauf folgt die Zieladresse, also beispielsweise ping heise.de. Der Befehl gibt pro Antwortpaket eine Zeile aus. Darin sind die Signallaufzeit in Millisekunden sowie die Anzahl der Zwischenstationen auf dem Pfad zum Ziel aufgeführt (Hops bei IPv6, TTL bei IPv4, siehe Kasten „Unterschiede zwischen IPv6 und IPv4“).
Wenn auf Windows und Linux beide Internet-Protokolle konfiguriert sind (IPv4 und IPv6, also Dual-Stack), schickt das Betriebssystem den Request per IPv6 ab. Mit den Optionen -6 und -4 erzwingt man eines der beiden Protokolle. Ältere Linuxe nutzen von Haus aus IPv4; für Pings per IPv6 verwenden sie ping6.
Der Windows-Befehl sendet in der Grundeinstellung vier Echo-Anfragen und stoppt dann. Der Linux-Befehl schickt Anfragen kontinuierlich, bis man ihn mittels Strg+C beendet. Alternativ lässt sich die Anzahl mit der Option -c begrenzen (z. B. ping -c 3 für genau drei Pings).
Wenn man auf Ping-Requests keine Antworten erhält, ist es zunächst offen, woran das liegt. Möglicherweise antwortet der Host nicht, aber es ist auch nicht auszuschließen, dass eine Firewall auf der Strecke zum Ziel den ICMP-Request nicht durchlässt. Das kann man mit dem Tool Traceroute genauer untersuchen. Traceroute nutzt den IP-Parameter Hop-Limit (bei IPv4 Time To Live, TTL genannt), um Antworten von bestimmten Routern zu erhalten, die den Pfad zum Host bilden.
Auf Windows lautet der Befehl tracert, auf Linux und macOS traceroute; danach folgt die Zieladresse. Der Windows-Befehl nutzt für die Pfadanalyse normalerweise ICMP-Pakete vom Typ Echo Request, also Ping-Pakete. Linux schickt hingegen UDP-Pakete mit Zielports ab 33434 aufwärts. Setzt man die Option -I, schaltet man auf Linux auf den Versand von ICMP-Echo-Requests um. Dafür sind Root-Rechte erforderlich.

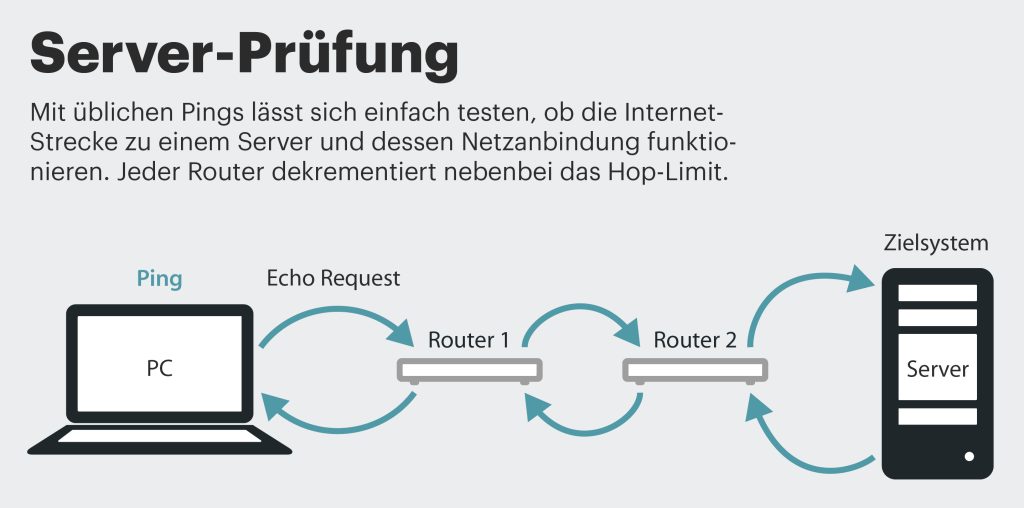
Eigentlich ist das Hop-Limit als Schutzfunktion und Warnmechanismus gedacht: Falls Netzbetreiber versehentlich eine Routing-Loop konfiguriert haben, würden Pakete, die in der Loop landen, sinn- und endlos darin kreisen. Deshalb werden IP-Pakete normalerweise mit einem Hop-Limit von zum Beispiel 64 oder 128 auf die Reise geschickt und jeder Router, der es empfängt, muss das Hop-Limit um 1 dekrementieren, bevor er es weiterreicht. Ist Hop-Limit 0 erreicht, darf ein Paket nicht weitergereicht werden, der Router muss es verwerfen. Zugleich sollte er den Absender des Pakets darüber mit der ICMP-Meldung „Time Exceeded/Hop Limit exceeded“ informieren. Ein Netzwerk-Admin kann dann anhand der Fehlermeldung der Ursache auf den Grund gehen.
Traceroute setzt das Hop-Limit ein, um Antworten von Routern auf dem Pfad zum Zielsystem zu erzwingen, die ein IP-Paket normalerweise stillschweigend weiterreichen. Dafür schickt der Befehl mehrere IP-Pakete zum Ziel. Er startet mit Hop Limit 1 und inkrementiert den Wert schrittweise um 1. Der erste Router, der das Paket mit dem Hop-Limit 1 empfängt, dekrementiert das Hop-Limit und muss es gleich verwerfen und dem Absender „Time Exceeded“ melden. Traceroute findet in der Antwort die IP-Adresse des ersten Routers und führt diese oder den DNS-Namen, den es per Reverse-Lookup zu ermitteln versucht, mitsamt der Latenzangabe in einer Zeile der Ausgabe auf.
Mit dem zweiten Paket (Hop-Limit 2) wird der zweite Router veranlasst, eine Fehlermeldung zu schicken. So geht es weiter, bis das Ziel erreicht ist. Pro Hop-Limit sendet Traceroute typischerweise drei Pakete.
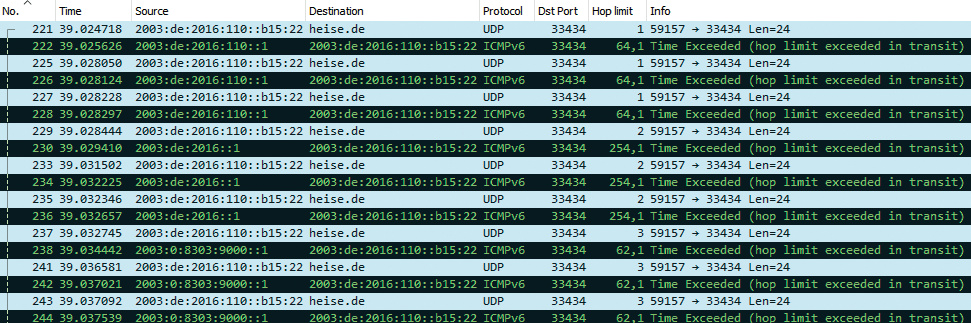
Im Beispiel „Traceroute in Wireshark-Ansicht“ ist das Ergebnis einer IPv6-Pfadanalyse zu heise.de im Netzwerkmonitor Wireshark zu sehen. Der Befehl sendet UDP-Pakete an Port 33434 (grau unterlegt). Darauf folgen die empfangenen Pakete (schwarz unterlegt). Quelle und Ziel (Source, Destination) der Traceroute-Pakete sind gleich, lediglich das Hop-Limit erhöht sich alle drei Pakete um 1. Die Antworten kommen per ICMPv6 und sind vom Typ „hop limit exceeded in transit“. Im Beispiel sind je drei dieser Meldungen von den ersten drei Routern entlang des Pfades zu sehen.
Detail am Rande: Auch die von den Routern gesendeten ICMPv6-Pakete haben ein Hop-Limit. Der erste und der dritte Router haben den Wert auf 64 gesetzt, der zweite auf 255. In der Ausgabe sind beim zweiten und dritten niedrigere Werte zu sehen (254 und 62), weil das Hop-Limit der Pakete unterwegs dekrementiert worden ist.
Wenn Traceroute innerhalb von 5 Sekunden keine Antwort von einem Router auf der Strecke erhält, markiert es diesen mit einem Stern (*). Diese Frist lässt sich mit der Option -w ändern. Wenn ein Router keine Fehlermeldung schickt, kann das an drei Dingen liegen: Der Admin hat diese Funktion deaktiviert, die Management-Plane des Routers ist überlastet oder eine Firewall blockiert die entsprechenden Pakete.
Applikations-Ping
Anstatt nur die IP-Verbindung zu einem Server zu prüfen (Schicht 3 im OSI-Modell), lässt sich auch der Server-Dienst mit einfachen Kommandos prüfen – das entspricht Pings auf Applikationsebene (Schicht 7 des OSI-Modells). Dabei verschickt ein Kommando echte Anfragen für einen Service, beispielsweise HTTP oder SMTP. Weil sich die Befehle über Skripte automatisieren lassen, lässt sich fortlaufend prüfen, ob etwa ein Webserver läuft, ohne in einem Browser wiederholt die F5-Taste zu drücken oder den Reload-Button zu klicken.
Die meisten Layer-7-Dienste setzen auf TCP oder UDP auf. Entsprechend verwenden auch die Tools TCP oder UDP. Weil UDP verbindungslos arbeitet, kann für den Test schon ein UDP-Paket genügen. Für TCP ist der übliche Drei-Wege-Handshake „SYN, SYN-ACK, ACK“ erforderlich.

Für den Test von Webservern ist das Tool httping gebräuchlich. Es sendet im Sekundentakt HTTP-Requests an den Zielserver. Ohne weitere Optionen fragt es nur den Header des Wurzelverzeichnisses „/“ ab (HEAD).
Der Befehl ist in diversen Linux-Repositories enthalten, beispielsweise Ubuntu. Oft sind die dort enthaltenen Versionen veraltet, weshalb wir empfehlen, die aktuelle Fassung der Software manuell zu installieren (zurzeit ist das Version 2.6):
|
1 2 3 4 5 |
sudo apt-get install libncursesw5-dev libssl-dev libfftw3-dev gettext git clone https://github.com/flok99/httping.git cd httping/ make sudo install |
Mac-User finden httping über die optionalen Paketmanager MacPorts und brew. Windows-Versionen kann man von der Seite des Entwicklers beziehen.
Im Beispiel „Webserver-Test“ ist zu sehen, wie httping den Webserver heise.de prüft. In der Ausgabe liefert es zum Beispiel die Latenz und den aktuellen Statuscode des Servers (im besten Fall ist das „200 OK“). Pro Zeile baut das Tool eine vollständige TCP-Verbindung gefolgt von einem HTTP-HEAD-Request auf. Jede Antwort belegt, dass die Internetverbindung sowie der Webserver grundsätzlich funktionieren.
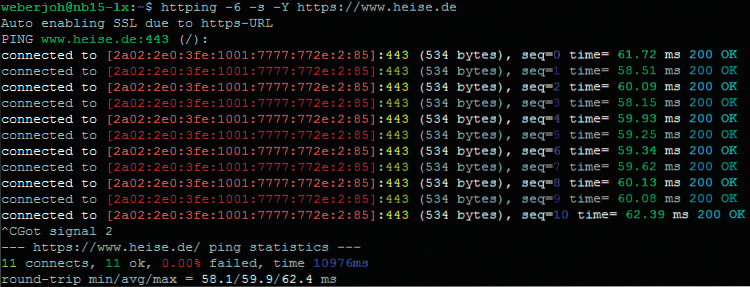
Um TLS-gesicherte Webseiten anzupingen, stellen Sie der Zieladresse https:// voran, beispielsweise httping https://heise.de. Mit den Optionen -s -Y lässt sich der HTTP-Status-Code farbig unterlegen.
Das Tool ist für gängige HTTP-Optionen ausgelegt. Es eignet sich auch für HTTP- und HTTPS-Verkehr über einen Proxy und kann die HTTP-Authentication prüfen.
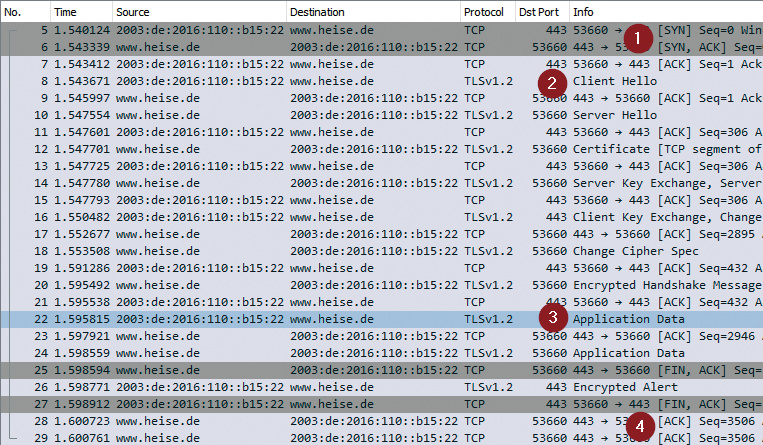
Bei einer TLS-Verbindung zu einem Webserver (siehe HTTPS-Test) gehen ganze 25 Pakete über das Internet. Zuerst läuft ein vollständiger TCP-Handshake ab (Phase 1, in Wireshark grau markiert), dann die TLS-Aushandlung (Phase 2). Dann wird der HTTP-Request gesendet (Phase 3). Zum Schluss baut das Tool die TCP-Sitzung ordnungsgemäß ab (Phase 4). Dennoch dauert ein Durchlauf bei gängigen Zielen in Deutschland nicht länger als 100 ms.
DNS-Server-Prüfungen
Mit dem in Python geschriebenen Tool dnsping lässt sich die Erreichbarkeit und Grundfunktion von DNS-Servern per DNS-Anfrage prüfen (Query). In der Grundeinstellung befragt dnsping den ersten konfigurierten Resolver nach einem A-Record des angegebenen Hosts. In der Ausgabe führt das Tool die Latenzen auf. Für die Abfragen verwendet es DNS-gemäß UDP, sodass für Hin- und Rückweg je ein Paket genügt.
Dnsping ist Teil der „DNS Diagnostics and Performance Measurement Tools“, kurz DNSDiag. Für Windows und macOS sind Binaries auf GitHub erhältlich. So installieren Sie es auf Linux:
|
1 2 3 4 |
sudo apt-get install python3-pip git clone https://github.com/farrokhi/dnsdiag.git cd dnsdiag/ pip3 install -r requirements.txt |
Für einen einfachen DNS-Ping an Ihren DNS-Resolver reicht die Angabe eines Hosts – etwa so: ./dnsping.py heise.de. Zusätzlich können Sie sich die DNS-Antwort ausgeben lassen -v, den anzufragenden DNS-Resource-Record festlegen -t <type> (standardmäßig A), den DNS-Server angeben -s <server> oder das Internet-Protokoll bestimmen -6/-4.
Das DNS-Protokoll kann alternativ TCP nutzen. Das ist bei Antworten erforderlich, die für UDP zu groß sind. Um eine TCP-Anfrage zu senden, setzt man die Option -T. Kommt die erwartete DNS-Antwort an, heißt das, dass Firewall und DNS-Resolver DNS-TCP-Pakete durchlassen, also korrekt konfiguriert sind.
Verwenden Sie in Ihrem Netzwerk einen DNS-Resolver, so verifizieren Sie mit diesem Tool dessen Verfügbarkeit und ermitteln die (grobe) Latenz. Im Heimbereich stellt jeder Router einen solchen Resolver bereit. So prüfen Sie, ob er funktioniert:
|
1 |
./dnsping.py -s 192.168.xxx.1 ct.de |
Der Parameter -s 192.168.xxx.1 legt die IP-Adresse des Routers fest. Bei den verbreiteten Fritzboxen ist das normalerweise 192.168.178.1, bei Speedports 192.168.2.1.
Nach dem gleichen Muster lassen sich öffentliche DNS-Resolver wie Googles Public-DNS (2001:4860:4860::8888 bzw. 8.8.8.8) oder OpenDNS testen (2620:0:ccc::2 bzw. 208.67.222.222). Anhand der Antworten lässt sich die Geschwindigkeit der DNS-Server vergleichen. Schnelle DNS-Server sind vorzuziehen, weil je umfangreicher Web-Seiten sind, desto mehr DNS-Anfragen geschickt werden müssen. Und je eher die DNS-Antwort da ist, desto eher kann ein Browser die jeweilige IP-Adresse aufrufen.

Auch aus dem Internet erreichbare autoritative DNS-Server lassen sich per dnsping testen. Geben Sie als Ziel die öffentliche IP-Adresse des Servers an und fragen Sie ihn nach einer der Domains, die er selbst verwaltet. Beispiel: Für ebay.de ist der DNS Server „a1.verisigndns.com“ zuständig.
Ihr eigener autoritativer DNS-Server sollte aus Sicherheitsgründen nicht auf Anfragen für sonstige Domains wie „heise.de“ antworten, da er dann als öffentlicher DNS-Resolver missbraucht werden kann. Für die Prüfung der DNSSEC-Validierung von Resolvern gibt es im gleichen Toolkit das Kommando dnseval. Weitere Details zu Tools aus der DNSDiag-Suite liefert die Webseite des Entwicklers (siehe ct.de/y8pp).
Mail-Server-Prüfungen
Um die Funktion eines SMTP-Servers fortlaufend zu prüfen, kann man das Kommando smtpping verwenden. Das Kommando ist via GitHub für Windows, macOS und Linux erhältlich und verschickt wie ein Mail-Client komplette E-Mails, liefert aber zusätzliche Statusinformationen.
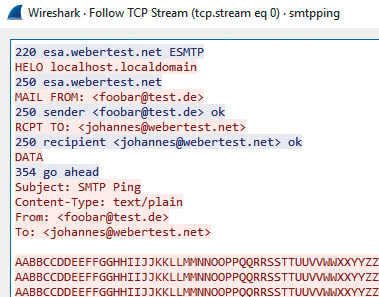
Wenn Sie dieses Tool in ein Skript einbauen, sollten Sie keine kurzen Test-Intervalle festlegen, weil SMTP-Server das wie eine SPAM-Welle auffassen können – im Weiteren blockieren SMTP-Server die Mail-Annahme von derart aufgefallenen IP-Adressen (Gray- oder Blacklist). Ein Beispiel für einen SMTP-Test sieht so aus:
|
1 |
./smtpping -c 4 -S foobar@test.de johannes@webertest.net @esa.webertest.net |
Der Parameter -c <count> legt die Anzahl der Prüfungen pro Programmstart fest. Im obigen Beispiel sind es vier Durchläufe. Darauf folgen die Absenderadresse -S <adresse> und die Empfängeradresse. Wird kein SMTP-Server per @<server> angegeben, schickt das Tool die Mail an die Adresse, die im MX-Record der jeweiligen Empfänger-Domain eingetragen ist.
Damit ein SMTP-Test funktioniert, muss der testende Rechner eine statische öffentliche IP-Adresse verwenden. Mails, die von dynamischen öffentlichen IP-Adressen eingereicht werden, verarbeiten SMTP-Server normalerweise nicht. Das ist eine seit Langem übliche Vorkehrung gegen den SPAM-Versand von Malware-befallenen privaten Rechnern.
Falls der Test-Rechner über eine dynamische öffentliche IP-Adresse mit dem Internet verbunden ist, kann man ersatzweise SMTP-Relays als Vermittler verwenden. Dafür trägt man am Ende der Befehlszeile ein @-Zeichen gefolgt von der IP-Adresse des Relays ein (z. B. @198.51.100.10).
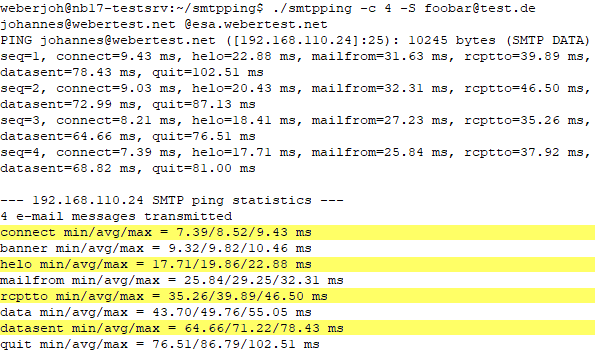
Smtpping führt in seiner Ausgabe auch Antwortzeiten des SMTP-Servers für jede der SMTP-Kommunikationsphasen auf. Sie sind in sechs Abschnitte unterteilt (connect, helo, mailfrom … ). Eine ungewöhnlich lange Verarbeitungsdauer einer Phase kann ein Hinweis auf einen Fehler sein.
Traceroute-Spezialitäten
Manche Security-Admins sperren den Ping-Verkehr zu öffentlichen Servern, die in ihrer DMZ stehen. Näher besehen bringt diese Sperrung bei einfachen Firewalls keine Security-Vorteile, denn der Server lässt sich von außen dennoch leicht identifizieren.
Das geht per Layer-4-Traceroute (engl. Layer Four Traceroute, LFT). Dafür genügt es, ein Päckchen an einen spezifischen TCP- oder UDP-Port eines Servers zu schicken. Dabei handelt es sich tatsächlich um gängige TCP-SYN-Pakete, und schlichte Firewalls lassen sie daher passieren. So kann man einen TCP-Aufbau mit einem Webserver simulieren, indem man ihm ein Päckchen an Port 80 schickt – das sieht aus wie der Beginn einer Browsing-Session.
Das hat Folgen für die Sicherheit der Infrastruktur hinter dem Internet-Router: Wenn dahinter auf dem firmeninternen Pfad zum Webserver Router stehen, dann lassen sie sich anhand von Paketen identifizieren, deren Hop-Limit beim Empfang 1 beträgt. Sie müssen dann das Hop-Limit dekrementieren und im Normalfall dem Absender des Pakets mit „ICMP Time Exceeded“ antworten. Einfache, Port-basierte Firewalls erkennen in einem zurück zur Quelle wandernden ICMP-Päckchen keine Gefahr und lassen es passieren. So tröpfeln Informationen über den firmeninternen Routing-Pfad innerhalb der DMZ nach draußen.

Um solche speziellen Traceroutes zu starten, sind auf Linux Root-Rechte erforderlich. Mit der Option -T schaltet man TCP ein, -U steht für UDP. Einen Webserver spricht man auf Port 80 oder Port 443 per TCP an -p <port>, einen DNS-Server auf Port 53 mit UDP. So testen Sie den HTTPS-Service von heise.de via IPv6:
|
1 |
sudo traceroute -6 -T -p 443 www.heise.de |
Sie möchten den Routing-Pfad zu einem SMTP-Server ermitteln? Schicken Sie einen Layer-4-Traceroute auf den TCP-Port 25 des Servers und lassen Sie sich überraschen, welche Unterschiede im Vergleich zu einem herkömmlichen Traceroute auftauchen.

DNS und Man-in-the-Middle
Eine Besonderheit im Zusammenhang mit Traceroute stellt der DNS-Dienst dar. Wenn DNS-Anfragen und -Antworten wie üblich per UDP übertragen werden, findet kein Layer-4-Handshake statt. So lässt sich eine DNS-Anfrage in einem einzigen UDP-Paket stellen.
Entsprechend kann ein Router, eine Firewall oder ein Intrusion-Prevention-System nicht nur das UDP-Protokoll mit Zielport 53, sondern auch die DNS-Anfrage lesen (wird im Klartext übermittelt) und unliebsame Anfragen blockieren, wenn es der Diktatur gefällt. DNS-Antworten können zudem gezielt gefälscht werden, um etwa auf staatliche Warn-Seiten umzuleiten.
Solche Manipulationen kann man mittels speziellen Traceroutes aufdecken: Man verschickt DNS-Anfragen und schaut per Hop-Limit-Inkrement, wie sie behandelt werden. Neben dem Routing-Pfad zum DNS-Resolver lassen sich auch manche Man-in-the-Middle-Angriffe beziehungsweise DNS-Spoofing-Attacken aufdecken.
Manipulationen erkennt man daran, dass die DNS-Antwort nicht vom eigentlichen DNS-Resolver kommt, sondern von einem normalerweise transparenten Infrastruktur-Element, das auf dem Pfad vor dem Resolver sitzt.
Derartiges DNS-Spoofing kann aber auch gewünscht sein. So bieten moderne Firewalls und DNS-Appliances ein Feature namens „DNS Sinkholing“ an, bei welchem DNS-Anfragen an Malware-Domains gezielt mit einer Dummy-IP-Adresse beantwortet werden, um den Benutzer zu schützen.
Für solche speziellen Analysen enthält die Suite DNSDiag das Tool dnstraceroute; auf Linux und Windows sind für die Ausführung Root-Rechte erforderlich. Testen Sie zuerst die Auflösung von gängigen Domains mit Ihrem üblichen DNS-Resolver:
|
1 |
sudo ./dnstraceroute.py heise.de |
Wie bei dnsping kann man den zu befragenden DNS-Server mit der Option -s <server> festlegen. Mit der Option -t <type> wählen Sie aus, welchen Resource Record der DNS-Server liefern soll (A = IPv4-Adresse, AAAA = IPv6-Adresse, MX = Domain des Mail-Servers).
Grundlegende Firewall-Empfehlungen

Daher dürfte die Security einer Firma nicht maßgeblich leiden, wenn ICMP-Pings von außen in die DMZ erlaubt sind. Es liegt auf der Hand: Wenn Ihr Webserver auf gängige HTTP- und HTTPS-Anfragen aus dem Internet antwortet, ist er ja ohnehin bekannt und ein ICMP-Ping verrät Angreifern nichts Neues. Das Gegenteil ist jedoch der Fall, wenn Ihr Server nicht über Standard-Ports erreichbar ist, sondern über spezielle, die nur bestimmte Nutzer kennen. Nur dann sollte man ICMP-Pings verbieten, weil sich dann ein verborgener Server mittels automatischer Abfragen schneller identifizieren lässt.
Zugriffe vom Internet in das LAN sind ohnehin tabu, egal ob für ICMP-Pings oder sonstigen Verkehr. Aber das haben Ihre Firewall-Administratoren hoffentlich schon immer so konfiguriert.
Neben klassischen Port-basierten Firewalls bieten „Next-Generation Firewalls“ zumindest für die Behandlung von Layer-4-Traceroutes sehr detaillierte Einstellungen. Beispielsweise erkennen sie sie unabhängig vom verwendeten Protokoll. Damit kann man sie einfach unterbinden und HTTPS weiterhin zulassen. Ein regulärer Web-Browser wird so Ihren Webserver wie gewohnt per TCP-SYN auf Port 443 erreichen. Ein Layer-4-Traceroute, der einen TYP-SYN auf Port 443 nur vortäuscht, scheitert hingegen. So bleiben interne Routing-Pfade von außen nicht einsehbar.
Für die Anwendung der Tools spielt das zwar keine Rolle, sollten Sie jedoch spezifische Filter für tcpdump, Wireshark oder ähnliche Tools bauen, müssen Sie genau zwischen dem Standard-Internet-Protokoll (IPv6) und dem veralteten IPv4 unterscheiden: Während ein IPv6-Ping die ICMPv6-Typen 128 (echo request) und 129 (echo reply) verwendet, nutzt man bei IPv4 die ICMPv4-Typen 8 (echo request) und 0 (echo reply).
Auch unterscheiden sich die Time-Exceeded-Pakete, die Traceroute verwendet. Bei ICMPv6 sind diese vom Typ 3 Code 0, bei ICMPv4 handelt es sich um Typ 11 Code 0.
Außerdem wird das Hop-Limit nur in IPv6-Headern verwendet. In IPv4-Headern steht hingegen „Time to Live“ oder kurz „TTL“. Es ist auch gut, dass man sich bei IPv6 vom TTL-Begriff getrennt hat, denn er bezeichnet keine Zeiteinheit.
TCP- und UDP-Pakete sind hingegen bei IPv6 und IPv4 gleich. Beide verwenden grundsätzlich die Felder Source- und Destination-Port. Auch auf Applikationsebene gibt es keine Unterschiede. Ein HTTP-Request, der per IPv6 übertragen wird, sieht exakt so aus wie bei IPv4.
Photo by Tim Mossholder on Unsplash.