
During my analysis of NTP and its traffic to my NTP servers listed in the NTP Pool Project I discovered many ICMP error messages coming back to my servers such as port unreachables, address unreachables, time exceeded or administratively prohibited. Strange. In summary, more than 3 % of IPv6-enabled NTP clients failed in getting answers from my servers. Let’s have a closer look:
I saw those ICMP packets in my traces for a while but did not think about it until I read this article from Heiko Gerstung: How to NOT use the NTP Pool. “[…] It sends an NTP client request, waits for a specific amount of time for the response and, if the response does not arrive within this time frame, closes the port and stops listening. If an NTP response arrives after the device stopped waiting for it, an ICMP Port Unreachable error message is sent to the sender of the NTP response, creating even more unnecessary traffic […].”

I wanted to have a deeper look into it. I captured all NTP traffic for 24 hours coming into my four NTP servers listed at the NTP Pool Project. (I was using my ProfiShark 1G in front of the FortiGate FG-100D that had those servers behind it.) I was quite astonished how many different ICMP error codes I found. Note that since I am using IPv6-only, you’ll only see ICMPv6 messages rather than legacy IP ones. Following is my analysis:
ICMP Errors ‘n Errors ‘n Errors
This is how my NTP tracefile looks in Wireshark. Different errors distributed all over the trace. Second screenshot filtered for “icmpv6” and a special custom column “ipv6.dst” but with 2nd field occurrence to display the original source that triggered the ICMPv6 error as my servers tried to reply:
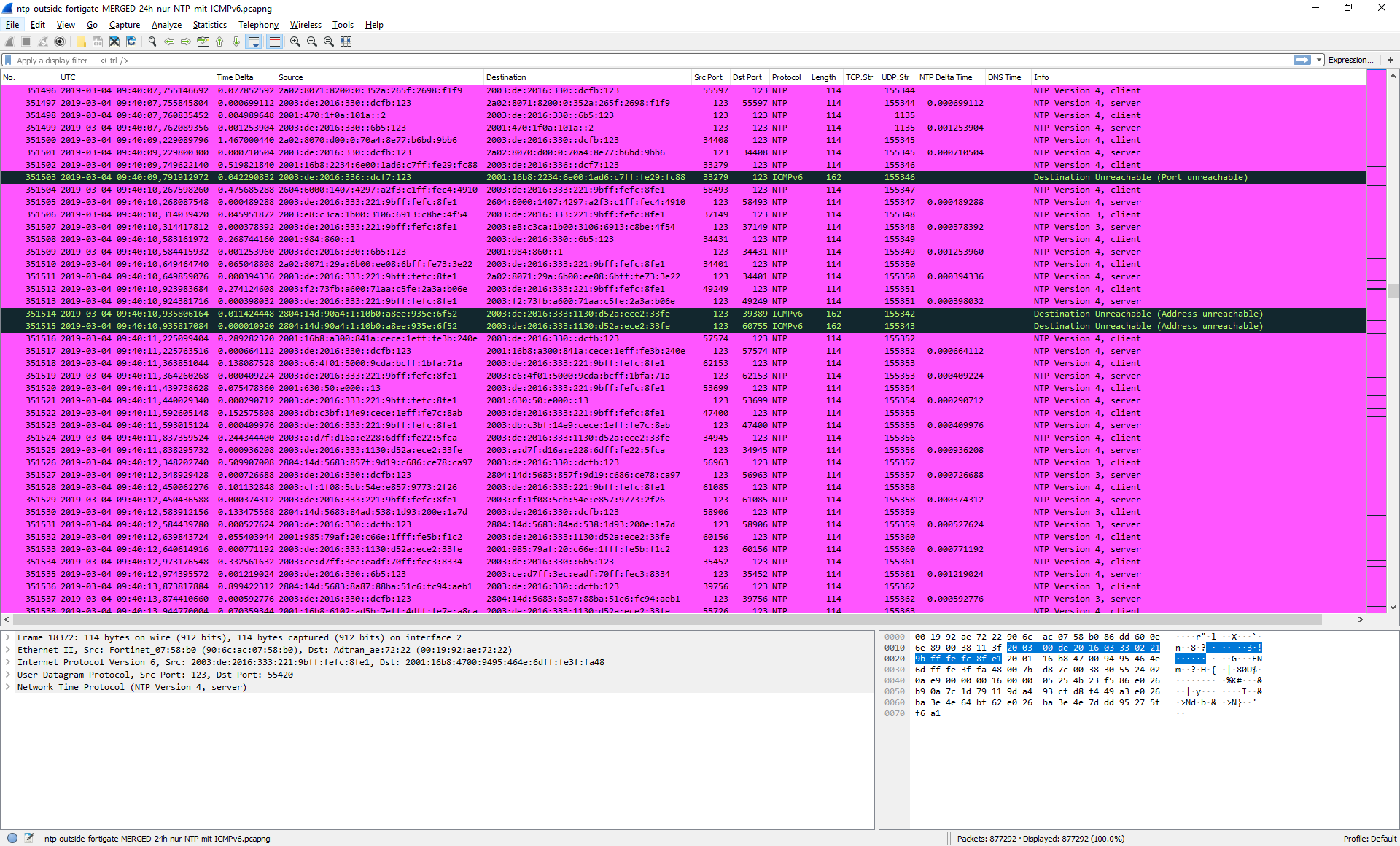

Leveraging tshark I was getting some stats about it:
- During that 24 h period 166471 unique source addresses queried my NTP servers
- My servers received ICMPv6 error packets from 5193 different sources! (That is: unique routers OR end nodes.)
- Doing the math it’s about 3.11 % of all NTP clients. Quite high to my mind.
- In summary, they received 10923 ICMPv6 error messages.
The distribution of those ICMPv6 types and codes was:
|
1 2 3 4 5 6 7 8 |
Count Type Code Meaning 385 1 0 no route to destination 291 1 1 communication with destination administratively prohibited 9839 1 3 address unreachable 367 1 4 port unreachable 3 1 5 source address failed ingress/egress policy 1 1 6 reject route to destination 37 3 0 hop limit exceeded in transit |
WHAT? This is almost every destination unreachable code that is available! ;D Uhm. This was not expected.
For the sake of completeness: This is how I used tshark along with sort, uniq, etc.:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
### Number of unique IPv6 source addresses which queried one of my four NTP servers tshark -r ntp-outside-fortigate-MERGED-24h-nur-NTP2345-mit-ICMPv6.pcapng -Y "!icmpv6 && (ipv6.dst == 2003:de:2016:330::6b5:123 || ipv6.dst == 2003:de:2016:330::dcfb:123 || ipv6.dst == 2003:de:2016:333:1130:d52a:ece2:33fe || ipv6.dst == 2003:de:2016:333:221:9bff:fefc:8fe1)" -T fields -e ipv6.src | sort | uniq | wc -l ### Number of unique IPv6 addresses that sent an ICMPv6 error tshark -r ntp-outside-fortigate-MERGED-24h-nur-NTP2345-mit-ICMPv6.pcapng -Y "icmpv6" -T fields -e ipv6.src | sort | uniq | wc -l ### Count of different error codes tshark -r ntp-outside-fortigate-MERGED-24h-nur-NTP2345-mit-ICMPv6.pcapng -Y "icmpv6" -T fields -e icmpv6.type -e icmpv6.code | sort | uniq -c 385 1 0 291 1 1 9839 1 3 367 1 4 3 1 5 1 1 6 37 3 0 |
Why?
To my mind, this is not only related to failures in NTP clients but to different IPv6 misbehavior in general. (For further reading, have a look at one of many other articles teaching the different types in general.)
- type 1, code 0: no route to destination: It seems to be a generic IPv6 problem based on the router to which the end-user network is attached to. Or the source address was spoofed and never valid at all. Looking into my trace: Many different sources were affected by this error while it was almost one single v6 router that sent out these errors. So maybe a single central router having routing issues?
- type 1, code 1: communication with destination administratively prohibited: Maybe some middleboxes (routers, firewalls) that do not work stateful? Probably not an NTP client problem but an administrative network issue. Looking into my trace this is almost one single source that triggered those errors. Hence no general problem.
- type 1, code 3: address unreachable: Again, generic IPv6 problem. For example when the layer 2 address is not resolvable (neighbor solicitation). Again, probably the original source address was spoofed, hence it did never exist. But that many? I have no idea why.
- type 1, code 4: port unreachable: Ok, this seems to be related to bad NTP client configurations such as shown here.
- type 1, code 5: source address failed ingress/egress policy: Why should someone block my source address?
- type 1, code 6: reject route to destination: Found that single one in my trace: The original source for this NTP query was “fdef:ffc0:4fff:1:dd91:bb7:2a77:d84”. This was discarded by my firewall on purpose. Again an IPv6 issue since someone configured this invalid source address.
- type 3, code 0: hop limit exceeded in transit: Again a generic IPv6 routing issue. But those affected clients can’t reach the Internet at all, can’t they?
If you want to have a look at those error messages you can download the trace file (with only the errors). 7zipped, 517 kb, 10923 packets:
![]()

(Trivia: Wireshark Filtering)
Note that I ran into some problems using Wireshark and tshark with its display filters since those are used for the ICMPv6 packets itself as well as the quoted original IPv6 packet (in my case: NTP). Complicated discussion about this on Twitter:
Need some help on #Wireshark filters for ICMPv6 messages: How can I distinguish between the src/dst from the ICMPv6 message vs. the original src/dst that's included in the packet as well? "Apply as Filter" is the same ipv6.dst ;( @PacketJay @SYNbit @geraldcombs @JeffCarrell_v6 pic.twitter.com/t6YLaGlv7c
— Johannes Weber 🎸 (@webernetz) April 4, 2019
Some possible solutions:
@webernetz. I have got a solution for tshark using "-T fields".
1) Create a column in Default Profile. Sample:
– Title: Source2, Type: Custom, Fields: ipv6.src, Occurrence: 2
2) Use -T fields -e _ws.col.Source2 to print the inner IPv6 source address from the icmp error message.— Matthias Kaiser (@wiresharky) April 4, 2019
OK. What about including the Ethernet source (or dest) address in the filter to help filter by direction? Something like so?:
icmpv6 && (ipv6.dst == …) && (eth.src == 00:11:22:33:44:55)
— Christopher Maynard (@chrisjmaynard) April 4, 2019
Conclusion
While I “just wanted to have a quick look at the ICMP errors” it took me a couple of hours to get just a little bit of knowledge out of this trace file. Sigh. I am not sure whether all my thoughts are 100 % correct.
Anyway, there are many different scenarios that lead to failures when it comes to IPv6 enabled NTP clients. To my mind, an error rate of more than 3 % is quite bad.
Featured image “3 o’clock” by Hani Amir is licensed under CC BY-NC-ND 2.0.
Some ICMP explanations.
NTP client programs such as ntpdate or sntp, these come from the NTP reference implementation, are often the cause of ICMP port unreachable messages. By design these programs run for a few seconds or less. NTP responses arriving after the client program has terminated may result in ICMP errors.
Organization may have more restrictive policies for incoming traffic than for outgoing traffic.