
I am participating in the NTP Pool Project with at least one NTP server at a time. Of course, I am monitoring the count of NTP clients that are accessing my servers with some RRDtool graphs. ;) I was totally surprised that I got quite high peaks for a couple of minutes whenever one of the servers was in the DNS while the overall rate did grow really slowly. I am still not quite sure why this is the case.
For one month I also logged all source IP addresses to gain some more details about its usage. Let’s have a look at some stats:
Prenotes
- For this blogpost I took the stats from March 2019. At this time, I had four servers online:
- ntp2: Stratum 1, Raspberry Pi 1 B+ with GPS
- ntp3: Stratum 1, Meinberg M200
- ntp4: Stratum 2, Raspberry Pi 3 B Rev 1.2
- ntp5: Stratum 2, Dell PowerEdge R200, Intel(R) Pentium(R) Dual CPU E2200 @ 2.20GHz, 4 GiB DDR2 Memory
- All were listed with a net speed of 10 Mbit/s. My actual ISP speed was 100 Mbit/s.
- Since all servers are IPv6 only, it is quite easy to count NTP clients. Every single source IPv6 address is a single client.

Scoring
NTP servers are only used by the round-robin DNS of the pool if they have a score higher than 10. But there are some concerns about this scoring. “Points are deducted if the server can’t be reached or if the time offset is more than 100ms (as measured from the monitoring systems).” More specific: “The monitoring system works roughly like an SNTP (RFC 2030) client, so it is more susceptible by random network latencies between the server and the monitoring system than a regular ntpd server would be.”
In fact, almost once a day my scores drop dramatically, sometimes even below a score of 0, while my NTP servers are fully functional from my point of view. Here’s an example from my server ntp5. The yellow dots (offset) are increasing regularly, while the score dropped between 14-23 o’clock on April 1st, 2019:

Now, this was my point of view from my monitoring station. [Ref: Basic NTP Server Monitoring] Neither the jitter (measured in µs rather than ms!) nor the offset (in ms) had any issues. April 1st, 2019 on the left-hand side of the graphs:

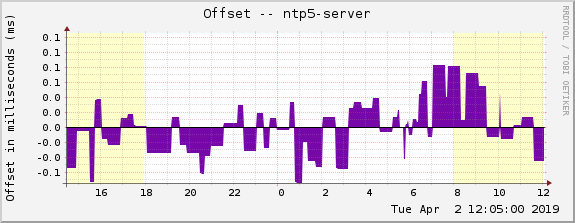
This seems to be related to some routing behavior from Los Angeles (the location of the NTP monitoring station) to my network (DTAG, AS3320). Or generic network congestion. I don’t know.
That is: My overall experience with this score is mixed. To my mind, it is not reliable and should be replaced by a more profound one. Note that this discussion is not new, refer to some threads on the pool mailing list: “Why is my server score suddenly so poor?” or “Decentralised monitoring?“.
NTP Client Stats
At first here is a weekly graph from one of my servers (ntp5) which shows the normal case all over the time. That is: High peaks (up to 30 k), but only for a very small amount of time:

Here is the summary graph of my NTP servers (ntp1, 2, 4, 5) from March 2019. It shows the maximum unique clients = IPv6 source addresses per 20 minutes. [Ref: Counting NTP Clients] That is: Max clients per 20 min is about 30-40 k. Wow.
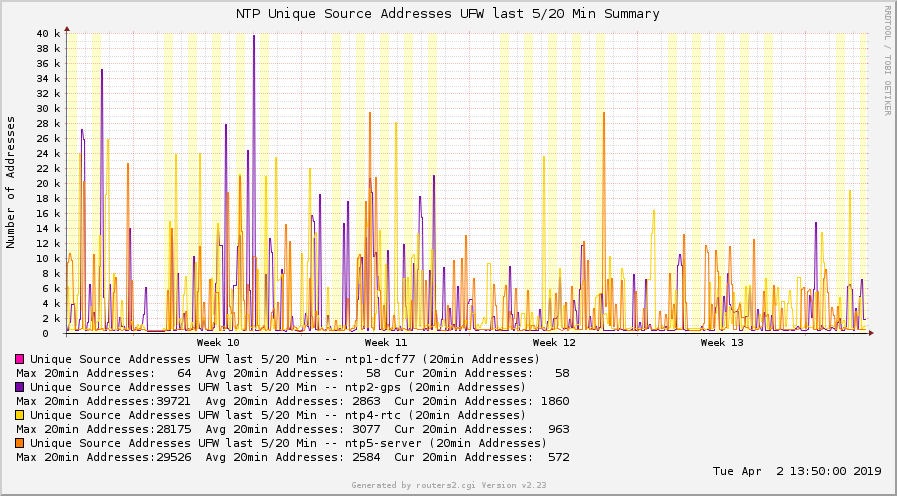
I have logged all incoming connections through my FortiGate FG-100D firewall to an external syslog-ng server. Hence I could cat ‘n grep through the raw logfiles from this whole month.

Some more details with the values per month:
| Server | NTP Requests | Unique Sources | Max Requests per Second |
|---|---|---|---|
| ntp2 | 2556621 | 973931 | 1794 |
| ntp3 | 3091628 | 1022346 | 1223 |
| ntp4 | 3077001 | 998343 | 1110 |
| ntp5 | 2555322 | 864274 | 1280 |
| AVG | 2820143 | 964723 | - |
| AVG per Day | 90972 | 31120 | - |
| AVG per Second | 1.05 | 0.36 | - |
Here are the top 10 queries per second timestamps from one server (ntp2). As you can see, it’s only the top 10 which exceeds the 1000 queries/s rate:
|
1 2 3 4 5 6 7 8 9 10 11 |
weberjoh@jw-nb10-syslog-mirror:/var/log/firewalls/2003:de:2016::3/2019/03$ cat * | grep "dstip=2003:de:2016:330::6b5:123 dstport=123" | awk '{print $5,$6}' | uniq -c | sort -rg | head 1794 date=2019-03-08 time=00:04:01 1702 date=2019-03-08 time=00:03:12 1547 date=2019-03-08 time=00:03:15 1528 date=2019-03-08 time=00:03:13 1444 date=2019-03-08 time=00:03:19 1280 date=2019-03-08 time=00:03:17 1266 date=2019-03-08 time=00:04:03 1130 date=2019-03-08 time=00:03:10 1064 date=2019-03-08 time=00:03:11 1061 date=2019-03-08 time=00:04:00 |
Here’s another analysis. How often do I see how many requests/s. First column: counts per month, second column: queries/s. Listing from ntp2. That is: The vast majority is below 10 queries/s. For example, line 11 reads: 829x per month the server got 10 requests per second. To my mind, that’s not that much.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
weberjoh@jw-nb10-syslog-mirror:/var/log/firewalls/2003:de:2016::3/2019/03$ cat * | grep "dstip=2003:de:2016:330::6b5:123 dstport=123" | awk '{print $5,$6}' | uniq -c | sort -rg | awk '{print $1}' | uniq -c | sort -rg | head -20 705352 1 158096 2 34087 3 10946 4 6838 5 3664 6 2054 7 1369 8 1076 9 829 10 724 11 636 12 573 13 501 14 460 15 435 16 412 17 351 18 349 19 316 21 |
This is how I grepped:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
### NTP requests per server address: cat * | grep "dstip=2003:de:2016:333:221:9bff:fefc:8fe1 dstport=123" | awk '{print $15}' | sed s/srcip=// | wc -l ### Unique source IPv6 addresses per server address: cat * | grep "dstip=2003:de:2016:333:221:9bff:fefc:8fe1 dstport=123" | awk '{print $15}' | sed s/srcip=// | sort | uniq | wc -l ### Queries per second, top 10 per server address: cat * | grep "dstip=2003:de:2016:333:221:9bff:fefc:8fe1 dstport=123" | awk '{print $5,$6}' | uniq -c | sort -rg | head ### How often are certain queries per second, top 20 per server address: cat * | grep "dstip=2003:de:2016:333:221:9bff:fefc:8fe1 dstport=123" | awk '{print $5,$6}' | uniq -c | sort -rg | awk '{print $1}' | uniq -c | sort -rg | head -20 ### Unique source addresses over all servers for one month: cat * | grep policy6 | grep "dstport=123" | awk '{print $15}' | sed s/srcip=// | sort | uniq | wc -l |
Requests after Leaving the Pool
I had to move my lab to another location with new IPv6 addresses. Hence I had to delete my servers since they are referenced by IP addresses rather than DNS names in the pool.
This is the NTP clients graph (zoomed in) for the first six days after I left the pool:

Clients are decreasing while there are still a couple of hundreds that are constantly using my server. Again, from a technical perspective I was expecting even many more clients using it constantly. I thought that once an NTP client queries the DNS name of the pool it stays on those resolved IP addresses until a reboot of the system. But obviously, this isn’t the case for the majority of clients. One idea: Maybe these clients use ntpdate rather than ntpd which is called every hour via cronjob? In this case, each run would initiate a new DNS query rather than staying on the same NTP server. But that’s just an idea. I have no clue what’s going on there.
Featured image “Hourglass with coins” by Marco Verch is licensed under CC BY 2.0.
Some modern NTP implementations provide two ways to specify an NTP Pool server. The historic method uses the “server” directive:
server 0.debian.pool.ntp.org # or other name to be resolved by DNS
A single server is chosen based on the name to IP address mapping performed when NTP initializes. If a server becomes unreachable it will remain in the association list.
Alternatively the “pool” directive can be used:
pool 0.debian.pool.ntp.org
The NTP software typically selects several NTP servers based on DNS resolution. During normal operation the NTP software may remove unreachable servers and requery DNS to find an alternative NTP server.
Interesting read. Are your aware of https://web.beta.grundclock.com/ ? It is a beta version of the monitoring system, with multiple vantage points. I wonder how it’s output compares to the production version in your case.