
As you hopefully already know, you should use at least three different NTP servers to get your time. However, there might be situations in which you can configure only one single NTP server, either via static IP addresses or via an FQDN. To overcome this single point of failure you can use an external load balancing server such as F5 LTM (in HA of course) to forward your NTP queries to one of many NTP servers. Here are some hints:
I am using a virtual F5 LTM with “BIG-IP 11.6.3.1 Build 0.0.7 Final”. My lab is IPv6-only.
The very Basics
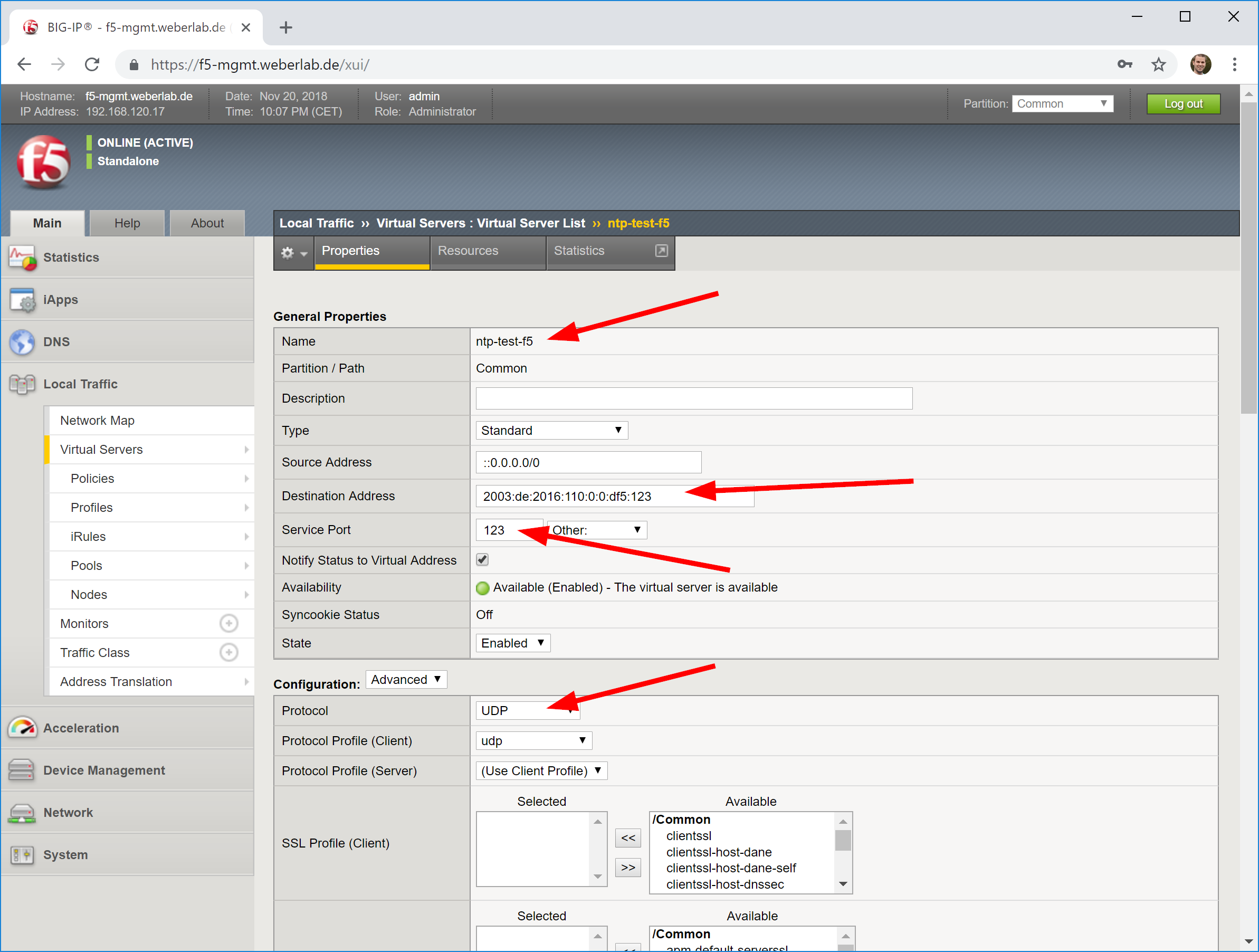
If you have an F5 you should be quite familiar with the first steps for a new virtual server:
- Add your NTP servers as nodes, health monitor can be node default called “icmp” (which in fact means: ping aka echo-request/response),
- add a pool with “udp” health monitor and those nodes in round robin with port 123 for NTP,
- create a new virtual server with a name, your desired destination address with service port 123 again, protocol “UDP”, source address translation to “Auto Map”, and the default pool to the just added pool, in my case called “ntp”.
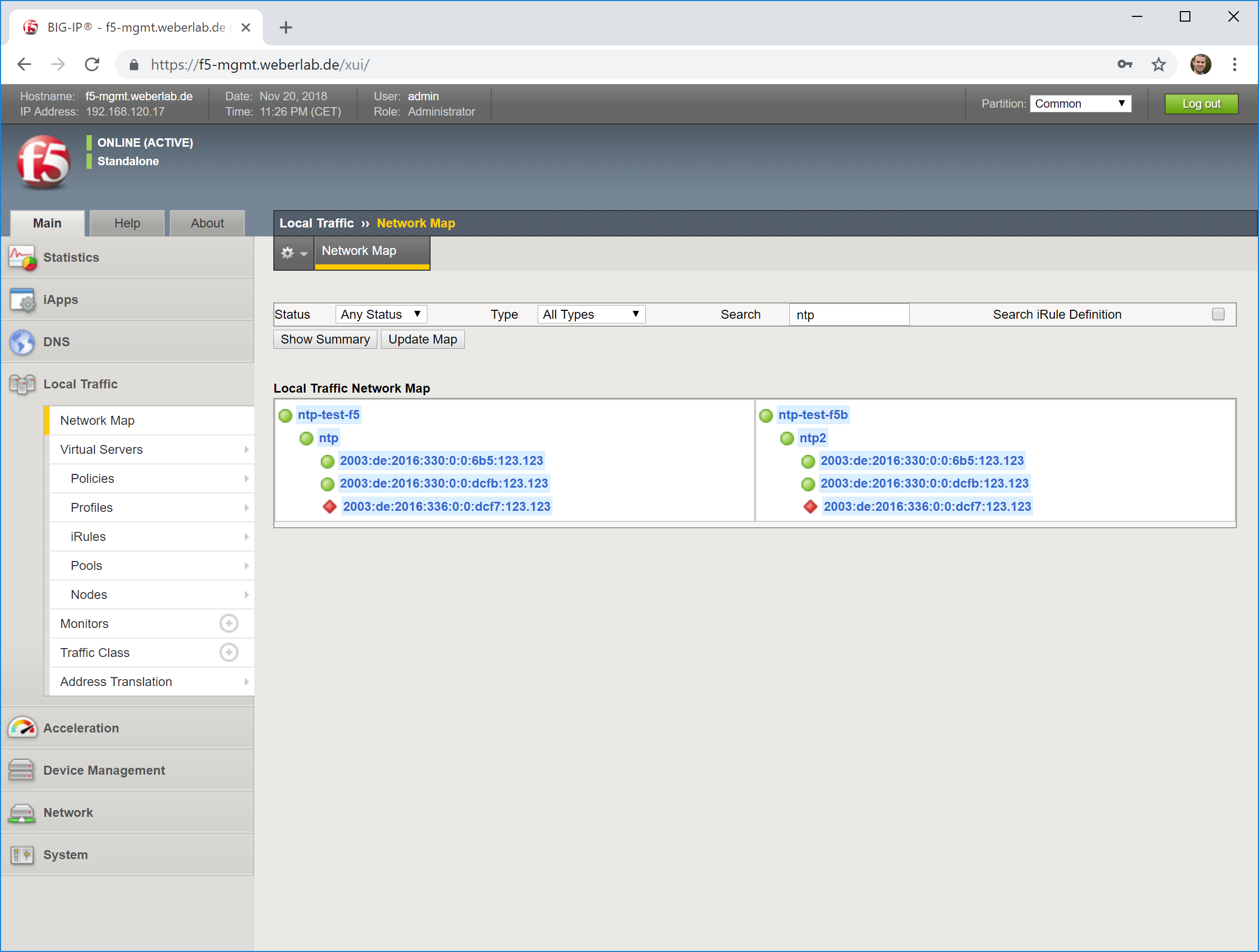
Looking at screenshots, it is like this:

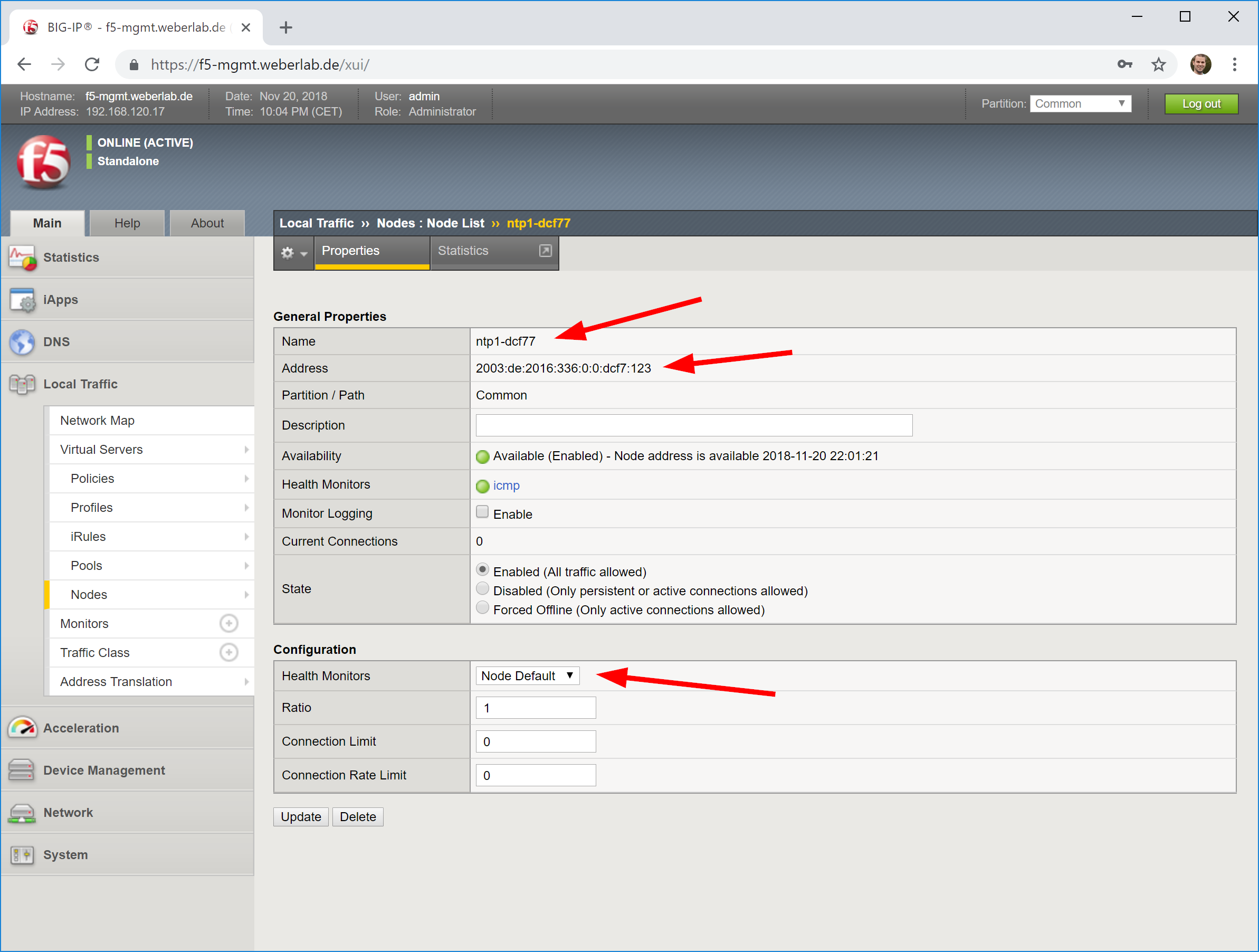
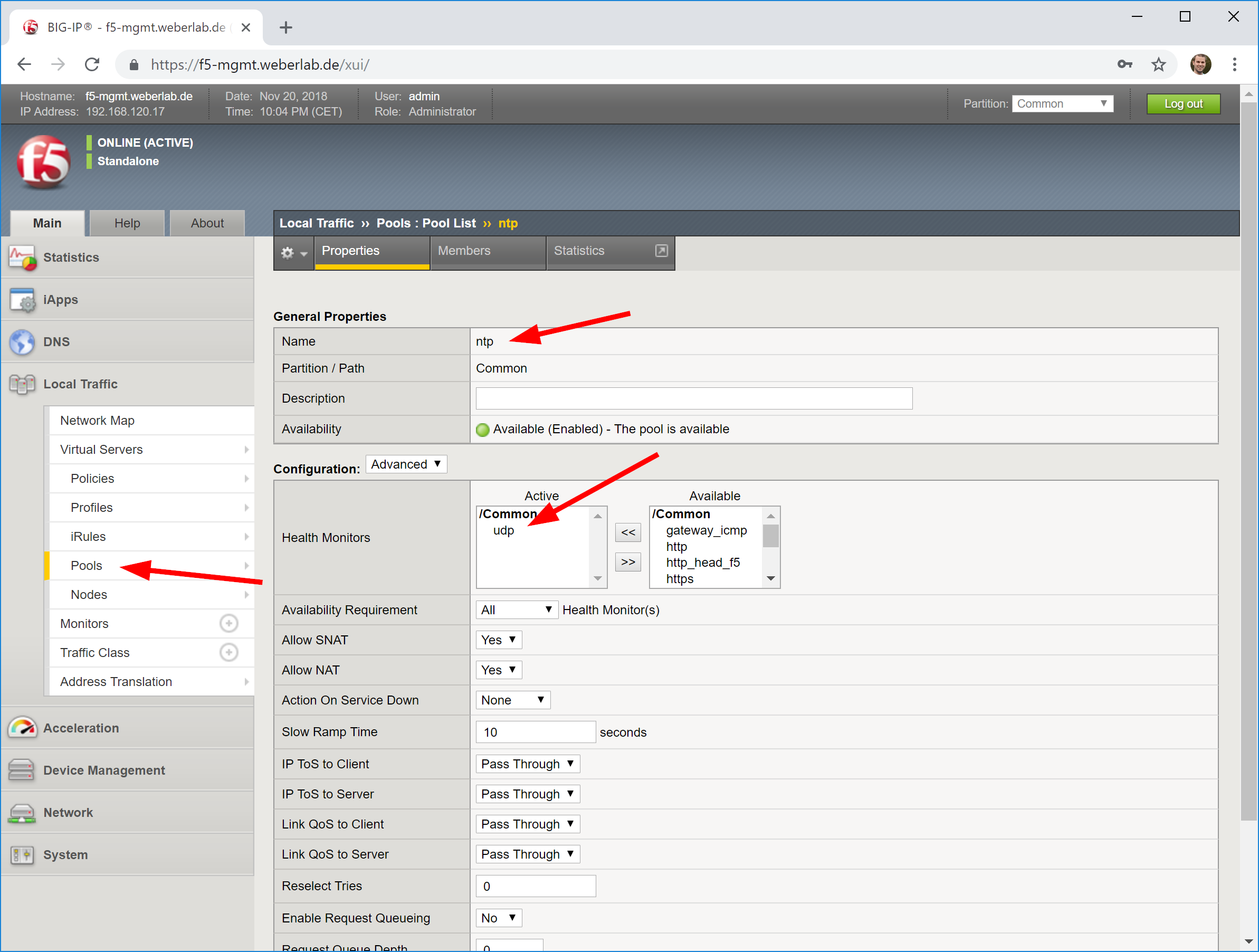
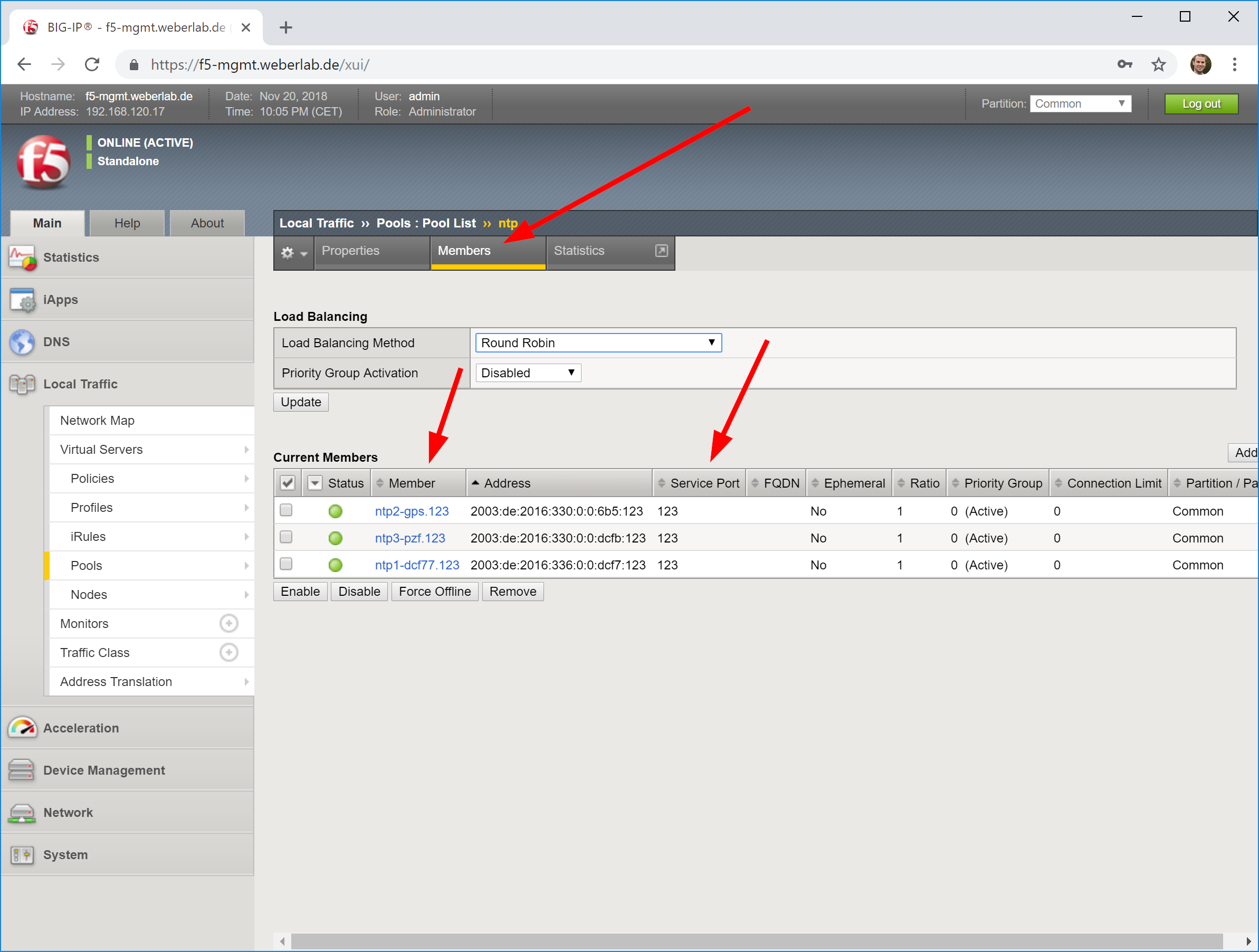
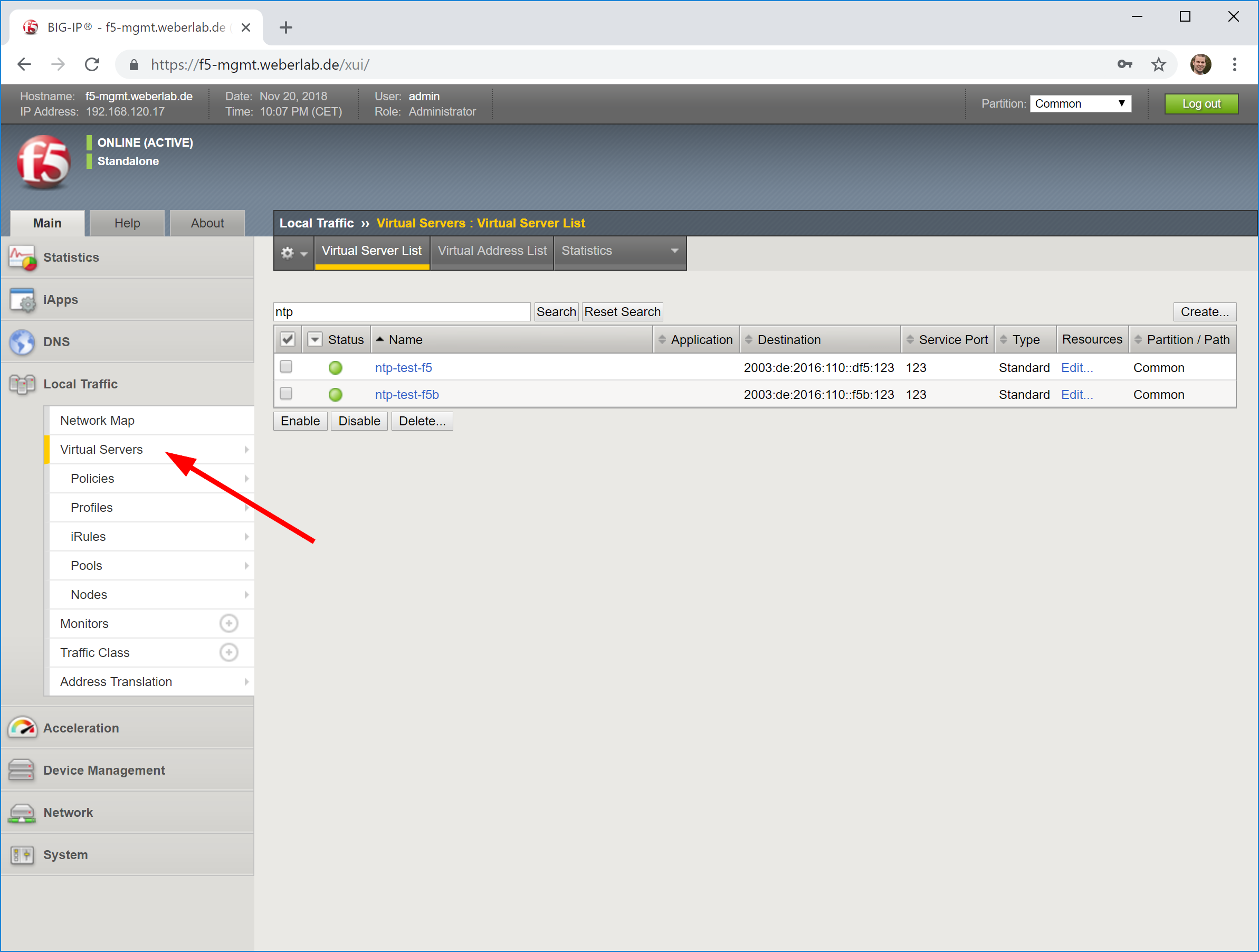

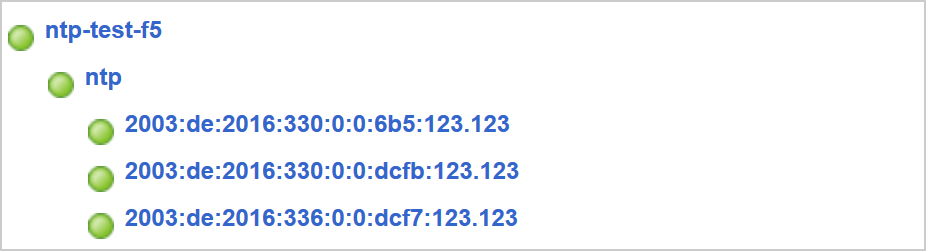
In the end, you’ll have a network map such as:
Your virtual NTP server should now work as expected. At least at a first glance, because you have some more things to do:

Persistence: Source Address Affinity
You should use some kind of persistency to have the same NTP client getting answers from the same NTP server over time. The best effort is to use a source address affinity, but with a longer timeout than the default. In case of NTP, clients are normally increasing the poll interval up to 1024 seconds. Therefore I created a new persistence profile (parent: source_addr) and customized the timeout to 1800 seconds:
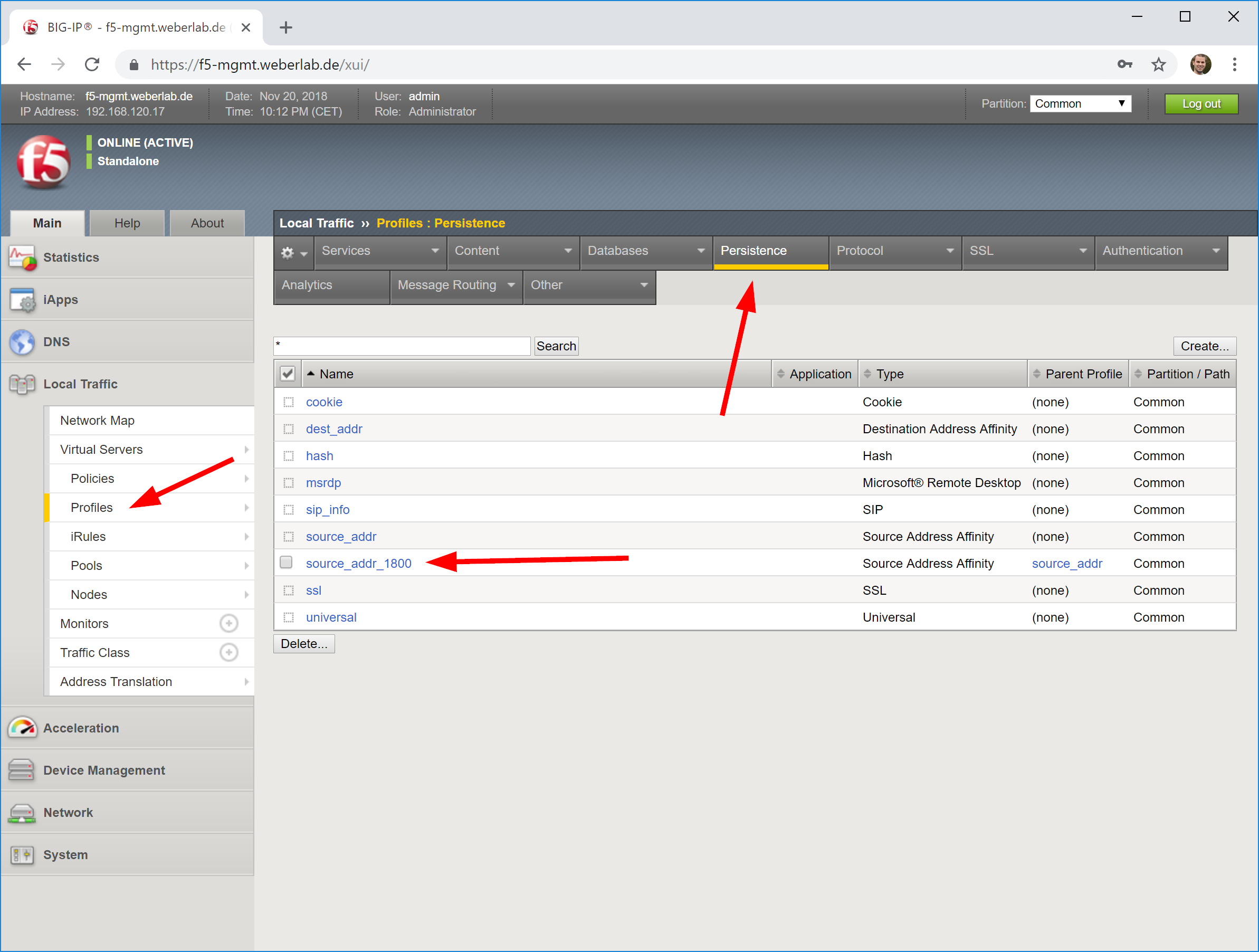


Now, each NTP clients gets its answers from the same NTP server as long as the interval is less than 1800 seconds.
Beware of the NTP Rate Limiting!
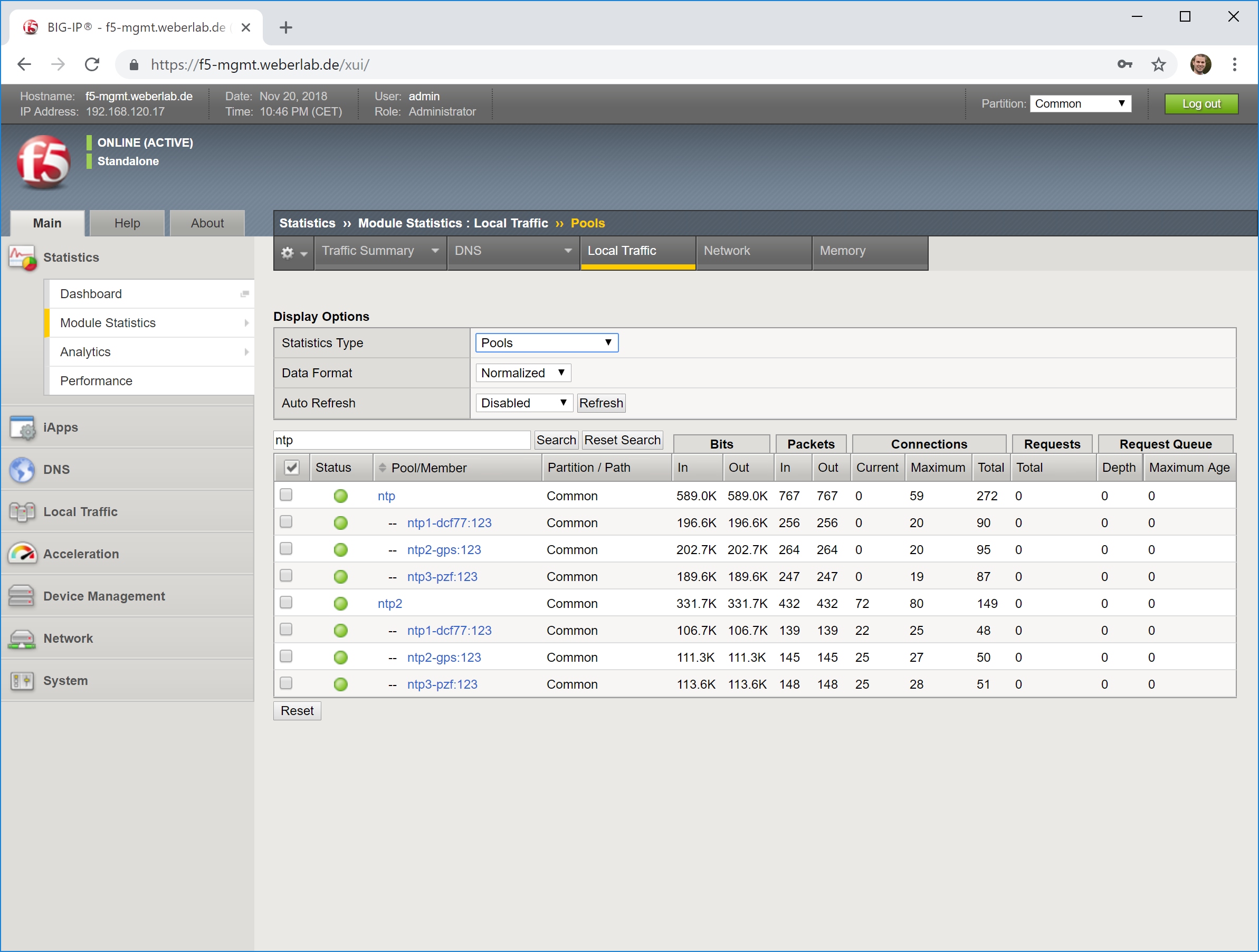
Note that the source IP address from the F5 itself will be rate limited on a default NTP server. As in my lab, I tested my F5 load balancing with 500 RIPE Atlas probes (click here for the measurement). With the defaults on the NTP server my two Raspberry Pis limited the rate of all connections from the F5 as you can see in the pools statistics: the in and out packets should match, but they didn’t, while the third NTP node (Meinberg LANTIME M200) answered to every single request:

On the NTP server itself you can see the L flag at the r column, which indicates the rate limiting for this F5 source:
|
1 2 3 4 5 6 |
pi@ntp1-dcf77:~ $ ntpq -c "mrulist limited" Ctrl-C will stop MRU retrieval and display partial results. Retrieved 7 unique MRU entries and 0 updates. lstint avgint rstr r m v count rport remote address ============================================================================== 14 449 3d0 L 3 4 837 41088 2003:de:2016:110::df5:0 |
To overcome this issue I “restrict”ed the source IPv6 address from the F5 to have all security settings as with the default settings but without the “limited” keyword. (Ref: NTP Access Control Commands and Options.) This listing shows the NTP default restrict (line 1) and my restrict for the F5 LTM:
|
1 2 |
restrict -6 default kod notrap nomodify nopeer noquery limited restrict 2003:de:2016:110::df5:0 kod notrap nomodify nopeer noquery |
Now, testing with 500 RIPE Atlas probes again (measurement here), all NTP clients got an answer. Yes! ;)

Stats
In the end you have created an NTP virtual server with a source persistence profile, while not limiting the requests to the NTP servers anymore. Congrats. Have a look at the stats and enjoy your life. Also note the tons of persistence records. ;)

However, please note that the health monitor of your NTP servers solely relies on ping! Since NTP is completely UDP based and F5 does not support real NTP health checks (such as verifying the “stratum” and “reach” of a server), this load balancing effort is only able to prevent complete NTP server failures, while not “server is up, NTP daemon is down” problems.
Featured image “Justitia” by eLKayPics is licensed under CC BY-NC-ND 2.0.
It’s good you included the caveat at the end re the limitations of f5 for proper health checks.
Also, if you are configuring the load-balancer to service a downstream NTP server, it will break any algorithm used by the lower strata server to check the best-accuracy time against multiple sources. Source address affinity and dynamic load-balancing like “least connections” etc may result in NTP queries being directed at a single host that’s drifted in accuracy.
For a downstream NTP server, you should insist to the powers-that-be that needs to connect to multiple sources for accuracy.
thank you this is excellent, and also helped me configure other loadbalanced UDP services.
Nice ;)
Nice to go through the article. I have a question – if NTP servers are using NTP Authentication keys , how to use those with this VIP ?
Kind Regards,
Aadi
Haha, that’s a VERY good question. ;)
(At first: NTP authentication with static keys is not used anymore at all. NTS is coming! https://weberblog.net/network-time-security-new-ntp-authentication-mechanism/ )
However, if you want to use symmetric keys, simply use the exact same keys with their exact same key IDs on all NTP servers. This should solve the issue.