Klemmt es im Netzwerk, so helfen Ping und Traceroute, Fehler und Engpässe einzukreisen. Wir erklären die Funktionsweise und helfen Angriffe aufzudecken.
Unter den Befehlen für Netzwerkanalysen gehören Ping und Traceroute zu den am häufigsten verwendeten. Die Ping-Funktion ist schnell beschrieben: Mittels ping <hostname|ip> schicken Sie ICMP-Pakete vom Typ Echo-Request vom Client zu einem Ziel. Das Ziel antwortet mit Echo-Reply-Paketen. Im Konsolenfenster erscheint dann unter anderem die Antwortzeit in Millisekunden (ms). Sie gibt an, wie viel Zeit vom Versenden bis zum Empfang der Quittung verstrichen ist. Und sie gibt die genaue Dauer eines Ende-zu-Ende-Dialogs an, die Round Trip Time, RTT.

Wenn Sie Ping eine Weile laufen lassen (unter Windows mit dem Parameter -t,unter Unix standardmäßig bis zum Abbruch per Strg+C), werden etwaige Stausituationen auf der betreffenden Internet-Strecke beziehungsweise Lastprobleme des angepingten Servers sichtbar. Aber Achtung: Ob eine entfernte Applikation überlastet ist oder nicht antwortet, darüber verrät Ping nichts.
Denn Ping-Pakete beantwortet der entfernte Netzwerk-Stack und die Ping-Laufzeit hängt – sofern nachgelagerte Router nicht verstopft sind – nur davon ab, ob der Stack zur Ping-Beantwortung noch Kapazitäten übrig hat. Client-Anfragen an einen Service beantwortet hingegen die zugehörige Applikation und die Auslastungen der beiden Elemente hängen nicht miteinander zusammen. Deshalb sollte man Fragen nach der Auslastung von Diensten mit Applikations-Pings wie httping, dnsping oder smtpping nachgehen.
- Die Bedienung der Monitoring-Werkzeuge Ping und Traceroute ist zwar gut dokumentiert, nicht aber die Auswertung der Ergebnisse.
- Vor allem bei Traceroute hilft Hintergrundwissen zu Backbone-Routern und zum Routing erheblich.
- Traceroute-Messungen gründen auf ICMP-Meldungen, die ursprünglich für ganz andere Dinge gedacht waren.
Der Traceroute-Befehl nutzt ein beim IPv6-Protokoll “Hop Limit” beziehungsweise bei IPv4 “Time To Live” genanntes Feld in den Headern der IP-Pakete. Beide hat man ursprünglich spezifiziert, um zu vermeiden, dass IP-Pakete endlos in versehentlich konfigurierten Routing-Loops kreisen und solche Loops verstopfen. Die Methode ist einfach: Der Absender gibt seinen IP-Paketen ein Hop Limit (maximale Anzahl von Zwischenstationen) von zum Beispiel 128 mit auf den Weg. Unterwegs dekrementiert jeder Router auf der Strecke den Wert um 1 und gibt dann das IP-Paket weiter. Kommt bei einem Router ein solches Paket mit Hop-Limit 0 an, muss er es verwerfen und dem Absender “Hop Limit Exceeded” melden. So ist gesichert, dass die IP-Pakete zwar weit reisen können, aber nicht endlos im Internet wabern und der Absender erfährt, dass die betreffende Strecke eine Endlosschleife enthält.
Der Befehl Traceroute nutzt diese Funktion, indem er IP-Pakete mit inkrementierendem Hop-Limit ab dem Wert 1 verschickt. So erzwingt Traceroute, dass sich alle Router auf dem Weg zum Ziel der Reihe nach melden; jeder einzelne schickt “Hop Limit Exceeded” zurück. Die Meldungen nutzt Traceroute, um die Laufzeit zu den Routern auf der Strecke zu ermitteln und überhaupt, um die Router zu identifizieren. Windows verschickt mit dem Traceroute-Befehl so wie Ping ICMP-Echo-Request-Pakete, Unix-Implementierungen verwenden UDP-Pakete mit Source-Ports beginnend ab 33434. Um Firewall-Blockaden zu umgehen oder um Policy Based Routings zu erkennen, bieten sich Layer-4-Traceroutes (LFT) an.
Antwortzeiten und Traceroute
Lange Antwortzeiten
Kommen wir zur gängigsten Fehlinterpretation von Traceroute: Schallt mal wieder der Ruf durchs Haus: “Schatz, das Internet is’ mal wieder lahm” und speziell die Verbindung zum Server X, schnappt man sich Traceroute und schaut sich die Antwortzeiten des Servers und der Router auf der Strecke dorthin an. Fallen die Antwortzeiten eines einzelnen Routers höher aus als bei den übrigen, glaubt man, das Problem identifiziert zu haben: Dieser Router beziehungsweise dessen Verbindungen sind überlastet. Oder noch schlimmer: Manche Router antworten gar nicht und erscheinen nur als Sternchen * in der Ausgabe. Dazu Auszüge eines Beispiels:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
tracert -4 -d netsec.blog 1 <1 ms <1 ms <1 ms 192.168.110.33 2 1 ms 1 ms <1 ms 192.168.7.1 3 5 ms 7 ms 3 ms 100.124.1.10 4 4 ms 3 ms 3 ms 100.127.1.147 5 5 ms 7 ms 3 ms 185.22.46.177 6 5 ms 3 ms 4 ms 80.81.192.239 7 8 ms 7 ms 7 ms 87.230.115.1 8 7 ms 7 ms 7 ms 87.230.114.4 9 35 ms 37 ms 35 ms 87.230.114.222 10 * * * Zeitüberschreitung der Anforderung. 11 7 ms 7 ms 7 ms 5.35.226.136 |
Dabei antwortet Hop Nummer 9 deutlich langsamer als vorherige Router und Hop Nummer 10 schweigt sogar. Hier ist doch eindeutig was kaputt im Internet, nicht wahr?
Leider weit gefehlt. Das erkennt man leicht daran, dass die Antworten des letzten Glieds der Kette konstant nach 7 ms eingehen. Dieser Wert steht für die Gesamtlatenz der untersuchten Strecke.
Wie kommt es dann aber, dass einzelne Router dazwischen weit langsamer antworten? Zunächst mal ist die Annahme falsch, dass die Antwortzeiten der einzelnen Router direkt mit der Verzögerung dieser Pfadabschnitte zusammenhängen. Denn tatsächlich bestehen moderne Hochgeschwindigkeitsrouter aus mindestens einer Data Plane und einer Control Plane. Das Weiterleiten von IP-Paketen, die Primäraufgabe von Routern, übernimmt die Data Plane, eine durch spezielle Hardware wie ASICs optimierte Einheit, die ihren Job sehr effizient und schnell erledigt. Die Data Planes befördern im Internet jegliche IP-Datenpakete, auch ICMP-Anfragen.
Kommt nun ein IP-Paket mit einem Hop-Limit von 1 an, wird es nicht weitergeleitet. Stattdessen setzt die Data-Plane den Wert auf 0 und verwirft das Paket gemäß der Spezifikation. Es ist dann die Control Plane, die “Hop Limit exceeded” an die Quelladresse meldet. Control Planes sind jedoch weit langsamer als der Rest des Routers. Eine hohe Latenz in der Traceroute-Ausgabe lässt also lediglich auf eine Überlastung der ohnehin schwächeren Control-Plane schließen – ist aber kein harter Beleg für einen Engpass im Routing. Und hat der Netzwerk-Admin eines Routers ICMP-Fehlermeldungen abgedreht, taucht dieser Router nur als Stern in der Traceroute-Ausgabe auf. Auch können ICMP-Antworten ausbleiben, wenn der Admin ein Rate-Limit gesetzt hat und der Schwellenwert bei Ihrer Messung gerade überschritten ist. Derart konfigurierte Router geben also keinen Rückschluss auf die Netzauslastung.
Wichtiges Detail: Anders als die übrigen Traceroute-Messwerte liefert die letzte Ausgabezeile dieselbe Aussage wie ein konventioneller Ping an das Zielsystem. Diesen Messwert steuert nämlich der Netzwerk-Stack des Empfängers per Echo-Reply bei und nicht ein Router beziehungsweise dessen Control-Plane.
Wenn aber ab einem Hop sämtliche nachfolgenden Router beispielsweise um 100 Millisekunden langsamer sind als vorherige, dann ist die Wahrscheinlichkeit hoch, dass ab diesem Router tatsächlich eine längere Laufzeit für alle Verbindungen besteht. Das kann man gelegentlich bei IP-Verbindungen beobachten, die per Unterseekabel um die halbe Welt gehen.

Traceroute-Wege
Wenn Sie klären wollen, ob es in Ihrem Firmennetz oder auf einer Internet-Strecke klemmt, so ist auch hier Traceroute die erste Anlaufstelle. Aber Achtung: Einerseits ist in großen Netzwerken und erst recht im globalen Internet asymmetrisches Routing üblich, andererseits gibt Traceroute nur die Messwerte für den Hinweg aus! Über den Rückweg vom Server zum Client, welcher ja rund die Hälfte der per Ping gemessenen Gesamtlaufzeit ausmacht, kann daher mit einer einfachen Traceroute-Messung keine Aussage getroffen werden.
Man kann nämlich nicht ausschließen, dass eine hohe Latenz ausschließlich auf ein lahmes Rückweg-Routing zurückgeht. Um also sowohl den Hin- als auch den Rückweg einer IP-Verbindung zu analysieren, braucht man zwei Traceroutes: Einen vom Client zum Server und einen vom Server zum Client (Applikations-Pings können nicht aufdecken, ob der Hin- oder der Rückweg lahmt). Dafür muss der Admin die Kontrolle über beide Enden haben, was im Heim- oder Firmennetz oft der Fall ist. Bei fremden Servern, die irgendwo im Internet stehen, ist das in der Regel nicht möglich. Zudem verhindert bei IPv4 die verbreitete Network Address Translation, die in Routern zwischen der öffentlichen IP-Adresse und dem privaten Netzwerk vermittelt, die Messung des Rückwegs zurück zum Client.
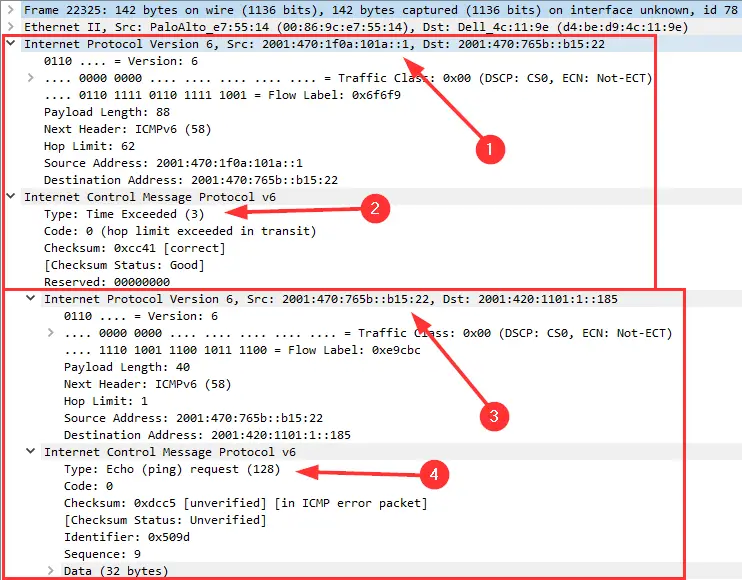
Dass sich zudem bei ICMP-Analysen Hinweg und Rückweg (für die Meldungen) ebenfalls unterscheiden können, sei nur ergänzend gesagt; sie können somit ebenfalls irreführende Messwerte liefern. Am Fazit ändert das wenig: Ein Traceroute liefert nur Hinweise, aber keine Beweise.
Und noch ein Eintrag für das kleine Know-how-Heftchen: Router senden die Hop-Limit-Exceeded-Meldungen immer von dem Interface aus, an dem das ursprüngliche Paket eingetroffen ist. Deshalb erscheinen in den Traceroutes je nach Verkehrsrichtung – stromauf- oder stromabwärts – verschiedene Absender-IP-Adressen. Das erschwert die Identifikation einzelner Router immens. Deshalb gebührt jenen Providern Dank, die den IP-Adressen der Router-Interfaces konsistente Hostnamen geben (Reverse DNS mittels PTR Records im weltweiten Domain Name System). Ohne die bleibt man auf Mutmaßungen zurückgeworfen.
Ping und Routing
Ping-Verwirrung
Ping hat den Vorteil, dass die ausgegebene Zeit den vollständigen Hin- und Rückweg abbildet. Dabei wird routingtechnisch genau derselbe Weg vermessen, den die Pakete von Applikationen entlang laufen, egal ob der aktuelle Pfad symmetrisch oder asymmetrisch ist. Vorsicht ist aber bei der Interpretation der TTL-Angabe geboten: Diese bezieht sich auf das vom Zielrouter neu verschickte Echo-Reply. Deshalb sagt dieser Wert nichts über den Hinweg aus. Aussagen wie “durch die TTL der Ping-Antwort wissen wir, dass der Server so und so viele Hops entfernt ist” treffen nicht zu.

Routing-Entscheidungen
Wieso gibt es überhaupt asymmetrisches Routing? Hierzu muss man zunächst die Funktionsweise von Routern und deren Forwarding-Entscheidungen verstehen: Jeder Router pflegt eine eigene Routing-Tabelle. Darin stehen entweder statische Routen (selten, beziehungsweise nur in kleinen Netzen) oder Einträge, die Protokolle wie OSPF (Open Shortest Path First in internen Netzen) oder BGP liefern (Border Gateway Protocol im weltweiten Internet).
Die Entscheidung, über welchen Weg ein Zielnetzwerk erreicht wird, fällt jeder Router eigenständig anhand seiner Routing-Tabelle – unabhängig von allen anderen Routern um ihn herum. Deshalb gilt: Nur weil Router A ein bestimmtes Zielnetz kennt, heißt das noch nicht, dass Router B dieses ebenfalls kennt. Und nur weil ein Router den Hinweg zu einem Zielnetz kennt, heißt das noch nicht, dass der Rückweg über die gleichen Router läuft.
Ein Netzwerk-Admin kann die Entscheidungen der einzelnen Router anhand diverser Parameter und deren Routing-Protokolle anpassen. Solange alle relevanten Netze zum gleichen Autonomen System (AS) gehören, hat der Admin volle Kontrolle. Wenn es allerdings um das Routing im Internet geht, wird es schwierig.
Beispielsweise kann eine Firma, die Anschlüsse von zwei verschiedenen ISPs verwendet und daher ihre Präfixe per BGP bekannt gibt, bestimmen, dass ausgehender Verkehr bevorzugt über Router 1 von ISP 1 läuft – den Router kontrolliert schließlich der Admin. Was die Rückrouten betrifft, anhand derer alle möglichen Router dieser Welt ihre Routing-Entscheidungen treffen, wird es schwierig bis unmöglich – schließlich stehen diese Router unter der Kontrolle anderer Admins. Im Internet sind daher asymmetrische Pfade eher der Standard als die Ausnahme. Zwar kann man das Path Pretend von BGP nutzen, um draußen zum Beispiel mitzuteilen, dass externe Router für die Rückroute den Pfad über ISP 2 nicht bevorzugen sollen. – viele ISPs richten sich sogar danach –, aber man kann es nicht erzwingen. De facto kommt Traffic trotzdem immer über beide ISPs zurück.

Möchten Sie wissen, über welche Autonomen Systeme Ihre IP-Verbindungen laufen? Lassen Sie Traceroute auf Unix mit der Option -A laufen, damit es die Nummern der AS (ASN) meldet. Technisch wird dabei die IP-Adresse des jeweiligen Routers per Whois-Befehl nachgeschlagen; die Adressen stecken in den Whois-Datenbanken von IP-Registraren wie dem RIPE. Häufig sind nur wenige Autonome Systeme beteiligt: Das AS Ihres ISP, ein bis zwei Transitnetzwerke sowie das AS des Ziels. Innerhalb eines AS-Netzwerks laufen die Pakete meist über mehrere, dem jeweiligen AS unterstellte Router.
Ping mit Traceroute
Ein hervorragendes Tool für das Netzwerk-Monitoring ist My traceroute, kurz mtr. Auf Linux installieren Sie es mit den Standard-Paketmanagern, auf macOS wahlweise via HomeBrew oder MacPorts. Windows Nutzer nehmen WinMTR. Das einfachste Befehlsmuster sieht wie bei ping oder traceroute aus: mtr heise.de.
In der Voreinstellung sendet das Tool sekündlich je 30 Ping-Pakete mit Hop-Limits von 1 bis 30. Es misst also den gesamten Pfad kontinuierlich und gibt die Antwortzeiten der einzelnen Hops in mehreren Spalten aus: letzter Ping, bester Wert, schlechtester Wert, Durchschnitt (Avg) und Standardabweichung (StDev).

Damit lassen sich etwaige Ausfälle auf dem Routingpfad live feststellen. Wenn ein paar Hops plötzlich schweigen und stattdessen Zeilen neuer Router auftauchen, dann ist das ein Beleg dafür, dass gerade ersatzweise eine neue Route eingeschlagen wurde.
Die zusätzliche Angabe des prozentualen Verlusts der Antwortpakete (Loss%) gibt einen Überblick über die empfangenen ICMP-Meldungen. Drücken Sie die Taste D zwei Mal, um die Anzeige des Display Mode so umzuschalten, dass er die letzten Ping-Laufzeiten farblich hervorhebt.

Angriffspunkt
In der Ausgabe von Traceroute sollte für jedes Netzwerksegment genau ein Router stehen. Bei IPv6 ist das durch die festen /64er-Masken einfach zu erkennen, bei IPv4 haben Sie zumindest in Ihren eigenen Netzen die Möglichkeit herauszufinden, wie die Subnetzmasken lauten. Sollten mal in einem Segment zwei Router stehen, stimmt etwas nicht. Entweder haben Sie dort wirklich mehrere Router – dann verfügen nicht alle über korrekte (statische) Routen – oder jemand hat einen Router als Man-in-the-Middle in Ihr Netz eingeschleust.
Dabei gibt sich ein Angreifer wahlweise via ARP-Spoof (IPv4) oder via NDP-Spoof (IPv6) als Default Router aus, wodurch er jedweden Traffic empfängt (Hop 1) und diesen an den echten Router weiterleitet (Hop 2), um die IP-Verbindungen nicht zu unterbrechen. So liest er alles mit, ohne gleich aufzufallen.
Aber was genau vorliegt, das bringen nur weitere Analysen zutage. Ein guter Startpunkt ist die Suche nach dem Switch-Port, an dem der verdächtige Router angeschlossen ist. Lesen Sie dazu im Client die MAC-Adresse des Default-Routers aus dem ARP-Cache aus und schauen Sie am Switch nach, über welchen Port diese MAC angesprochen wird. Dann lesen Sie die MAC Ihres tatsächlichen Default-Routers aus und vergleichen diese mit der vom Client verwendeten. Wenn sich die beiden unterscheiden, verfolgen Sie das Kabel vom verdächtigen Switch-Port, um den überzähligen und vermutlich eingeschleusten Router zu finden.

Eine Beispielausgabe für ein Traceroute ohne zusätzlichem Router sieht so aus:
|
1 2 3 |
tracert 2001:db8:72ed:a9d7:ba3f:57be:af5b:de2f 1 <1 ms 1 ms 1 ms 2001:db8:72ed:46::1 2 1 ms 1 ms 1 ms 2001:db8:72ed:a9d7:ba3f:57be:af5b:de2f |
Und so sieht die Ausgabe aus, wenn ein zusätzlicher Router im Segment steckt:
|
1 2 3 4 |
tracert 2001:db8:72ed:a9d7:ba3f:57be:af5b:de2f 1 1 ms <1 ms <1 ms 2001:db8:72ed:46:5d31:5dc1:315:13ef 2 1 ms 1 ms 1 ms 2001:db8:72ed:46::1 3 1 ms 1 ms 1 ms 2001:db8:72ed:a9d7:ba3f:57be:af5b:de2f |
Wireshark und tcpdump
Ein letzter Tipp zum Abschluss: Wenn Sie den Verkehr mit Wireshark oder tcpdump mitschneiden, dann lohnt sich meistens die Angabe eines Capture-Filters, um nicht gleich alle, sondern nur die relevanten Pakete mitzuschneiden. Gängig sind Filter unter Angabe der Quell- und/oder Ziel-IP-Adressen sowie der TCP-/UDP-Ports, beispielsweise host 192.168.1.10 and host 8.8.8.8 and port 53.
Doch mit solchen Filtern fängt man leider gar keine ICMP-Fehlermeldungen ein. Dabei ist leicht vorstellbar, dass ein Router auf dem Pfad nützliche ICMP-Pakete sendet, die sogar beim mitschneidenden Gerät ankommen – ohne geeigneten Filter werden sie aber ignoriert. Lösung: Immer den Zusatz or icmp or icmp6 an das Ende des Filters anhängen. So greift man alle ICMP- und ICMPv6-Pakete ab (im Filter ohne v geschrieben, also icmp6), egal von welcher Quell-IP-Adresse sie stammen. So kommen Sie bei Ihrer späteren Analyse in Wireshark versteckten Problemen außerhalb der eigentlichen IP-Sessions auf die Schliche.

Soli Deo Gloria!
Photo by Chris Liverani on Unsplash.
Toller Artikel!
Trotz langjähriger Erfahrung waren mir ein paar Details noch nicht bekannt.
Do you have this article in English?
Thanks!
It’s on my list. But don’t expect it within the next weeks. 🙈
No problem at all. Thanks for the update.
If you are using the Chrome browser you can right click and select “Translate to English” and the results are very good. Not sure whether other browsers have the same feature.