
Now that you have your own NTP servers up and running (such as some Raspberry Pis with external DCF77 or GPS times sources) you should monitor them appropriately, that is: at least their offset, jitter, and reach. From an operational/security perspective, it is always good to have some historical graphs that show how any service behaves under normal circumstances to easily get an idea about a problem in case one occurs. With this post I am showing how to monitor your NTP servers for offset, jitter, reach, and traffic aka “NTP packets sent/received”.
Note I am not yet “counting NTP clients” (which is very interesting), since the mere NTP software is not handing out such values. The “monstats” or “mrulist” do not fit this use case at all. I’ll have an upcoming blog post about this topic solely.
Please note: While I am still using my outdated SNMP/MRTG/RRDtool installation, you can get the idea in general while you should use your own monitoring tool for those purposes. I won’t recommend MRTG/Routers2 in 2019 anymore. Please DO NOT simply install MRTG by yourself but use other, more modern, monitoring services such as Icinga 2, Zabbix, or the like. However, everything I am showing with these tools can be monitored with any other SNMP-like system as well. You should also note that MRTG queries all values every 5 minutes. Since the monitored objects here are NOT an “average over the last 5 minutes” (such as mere interfaces counters from switches are) but a single value at the time of asking, all graphs show only parts of the truth – in discrete steps of 5 minutes. ;) Final note: Thanks to David Taylor and his page about Using MRTG to monitor NTP, which gave me the first ideas.

How to monitor NTP Servers?
Besides monitoring the generic Linux operating system stuff such as CPU, memory, load average, and network bandwidth, you have at least two different methods in getting some telemetry data from the NTP service to your monitoring station:
- Calling ntpq from the monitoring station in order to get some data from the remote NTP server. You must use the “restrict” option on the NTP server within ntp.conf to permit the monitoring station to query data, such as restrict 2003:de:2016:120::a01:80 in my case. The monitoring server is then able to use ntpq with a remote host such as ntpq -c rv ntp1.weberlab.de. In fact, these are normal NTP packets on the wire, but with NTP mode = 6, called “control message”. Refer to my blog post “Packet Capture: Network Time Protocol“.
- Using some scripts on the NTP server itself to hand out data to other protocols, such as SNMP. For example, I am using the “extend-sh” option within the snmpd.conf configuration on the NTP server to have the monitoring server query normal SNMP OIDs for certain NTP related information.
In any case, you must use some tools to grep ‘n sed through the output to extract exactly the values you are interested in. Furthermore, you need to feed those values into your monitoring tool. I am showing some MRTG config snippets along with RRDtool graphs.
For details about offset, jitter, and reach in general please have a look at the following blog post from Aaron Toponce, who describes all those values quite good: Real Life NTP.
Offset and Jitter
Offset: “This value is displayed in milliseconds, using root mean squares, and shows how far off your clock is from the reported time the server gave you. It can be positive or negative.” -> Since I am monitoring a stratum 1 NTP server (with a directly attached reference clock receiver), the offset shows the difference between this reference clock and the system time. Assumed that the system time is quite linear, the offset shows the variance from the received reference clock signal.
Jitter: “This number is an absolute value in milliseconds, showing the root mean squared deviation of your offsets.”
For those two values, I am using ntpq on the monitoring server itself. Note that the ntpq tool changed the count of position after decimal point some years ago. Some old ntpq might return something like “offset=-0.306”, while a newer ntpq is returning “offset=-0.306155”.
Basically, “ntpq -c rv” displays the system variables from the NTP server, such as:
|
1 2 3 4 5 6 7 8 9 |
weberjoh@nb15-lx:~$ ntpq -c rv ntp2.weberlab.de associd=0 status=0118 leap_none, sync_pps, 1 event, no_sys_peer, version="ntpd 4.2.8p12@1.3728-o Thu Nov 8 11:50:39 UTC 2018 (1)", processor="armv6l", system="Linux/4.14.71+", leap=00, stratum=1, precision=-18, rootdelay=0.000, rootdisp=1.060, refid=PPS, reftime=df9022bd.d28a1635 Fri, Nov 9 2018 16:14:05.822, clock=df9022c2.0df2e132 Fri, Nov 9 2018 16:14:10.054, peer=61582, tc=4, mintc=3, offset=0.005970, frequency=-7.553, sys_jitter=0.003815, clk_jitter=0.005, clk_wander=0.002 |
You can see the offset and sys_jitter in the second to last line. Using grep ‘n sed you can extract those values only:
|
1 2 3 4 |
weberjoh@nb15-lx:~$ ntpq -c rv ntp2.weberlab.de | grep offset | sed s/.*offset.// | sed s/,.*// 0.004919 weberjoh@nb15-lx:~$ ntpq -c rv ntp2.weberlab.de | grep sys_jitter | sed s/.*jitter.// | sed s/,// 0.003815 |
Since those offset values are that small, I am monitoring them in µs rather than in ms! Now for my MRTG installation, this “Target” has the following config for the offset in µs:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
############################################################### ################### Offset µ Microseconds ##################### ############################################################### Target[ntp2-gps-offset-us]: `ntpq -c rv ntp2.weberlab.de | grep offset | sed s/.*offset.// | sed s/,.*// && echo 0` * 1000 #Max only 0.1 seconds = 100 ms = 100000 us MaxBytes[ntp2-gps-offset-us]: 100000 Title[ntp2-gps-offset-us]: Offset µs -- ntp2-gps Options[ntp2-gps-offset-us]: gauge Colours[ntp2-gps-offset-us]: DARKPURPLE#7608AA, Blue#0000FF, BLACK#000000, Purple#FF00FF YLegend[ntp2-gps-offset-us]: Offset in microseconds (µs) Legend1[ntp2-gps-offset-us]: Offset Legend3[ntp2-gps-offset-us]: Peak Offset LegendI[ntp2-gps-offset-us]: Offset: ShortLegend[ntp2-gps-offset-us]: µs routers.cgi*Options[ntp2-gps-offset-us]: fixunit nototal noo routers.cgi*ShortDesc[ntp2-gps-offset-us]: Offset µs ntp2-gps routers.cgi*Icon[ntp2-gps-offset-us]: graph-sm.gif |
as well as for the jitter, in µs, too:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
############################################################### ################### Jitter µ Microseconds ##################### ############################################################### Target[ntp2-gps-jitter-us]: `ntpq -c rv ntp2 | grep sys_jitter | sed s/.*jitter.// | sed s/,// && echo 0` * 1000 #Max only 0.1 seconds = 100 ms = 100000 us MaxBytes[ntp2-gps-jitter-us]: 100000 Title[ntp2-gps-jitter-us]: Jitter µs -- ntp2-gps Options[ntp2-gps-jitter-us]: gauge Colours[ntp2-gps-jitter-us]: TURQUOISE#00CCCC, Blue#0000FF, DARKTURQUOISE#377D77, Purple#FF00FF YLegend[ntp2-gps-jitter-us]: Jitter in microseconds (µs) Legend1[ntp2-gps-jitter-us]: Jitter Legend3[ntp2-gps-jitter-us]: Peak Jitter LegendI[ntp2-gps-jitter-us]: Jitter: ShortLegend[ntp2-gps-jitter-us]: µs routers.cgi*Options[ntp2-gps-jitter-us]: fixunit nototal noo routers.cgi*ShortDesc[ntp2-gps-jitter-us]: Jitter µs ntp2-gps routers.cgi*Icon[ntp2-gps-jitter-us]: link-sm.gif |
Note that the offset can be positive and negative! Hence the rrd file for MRTG must be tuned to support negative values:
|
1 2 3 4 5 6 |
sudo rrdtool tune /var/mrtg/ntp2-gps-offset-us.rrd --minimum ds0:-100000 # viewing the file with rrdtool: rrdtool info /var/mrtg/ntp2-gps-offset-us.rrd # should indicate something like this: ds[ds0].min = -1.0000000000e+05 ds[ds0].max = 1.0000000000e+05 |
In the end, my offset graphs look like this: (2x DCF77 daily/weekly, having offsets of +/- 1000 µs = 1 ms, and 2x GPS daily/weekly, having offsets of +/- 1 µs!!!)
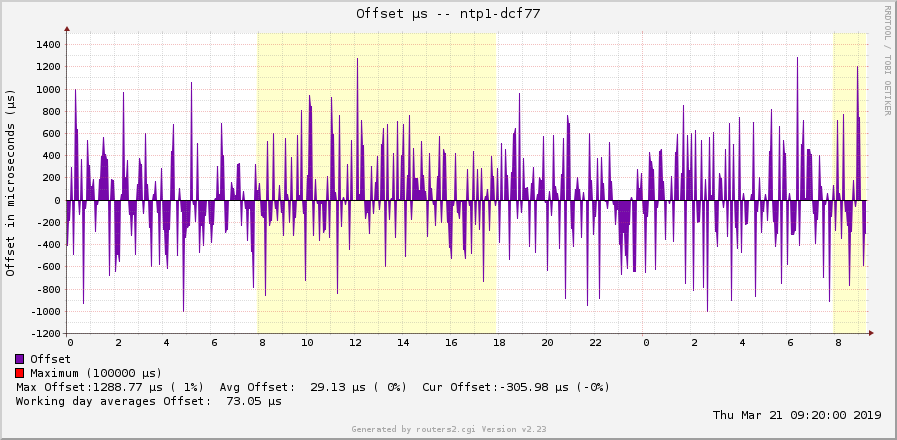


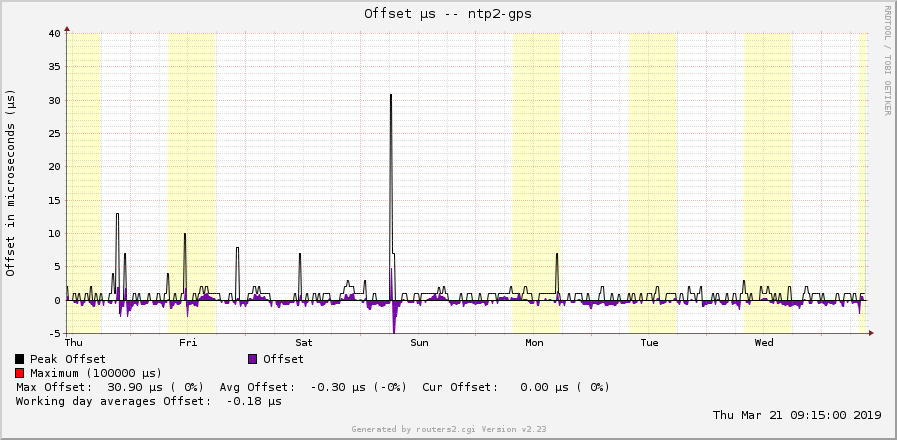
While the jitter graphs are as follows: (Again 2x DCF77 daily/weekly with jitter of about 1000 µs = 1 ms, and 2x GPS daily/weekly with jitter of about 2 µs!!!)
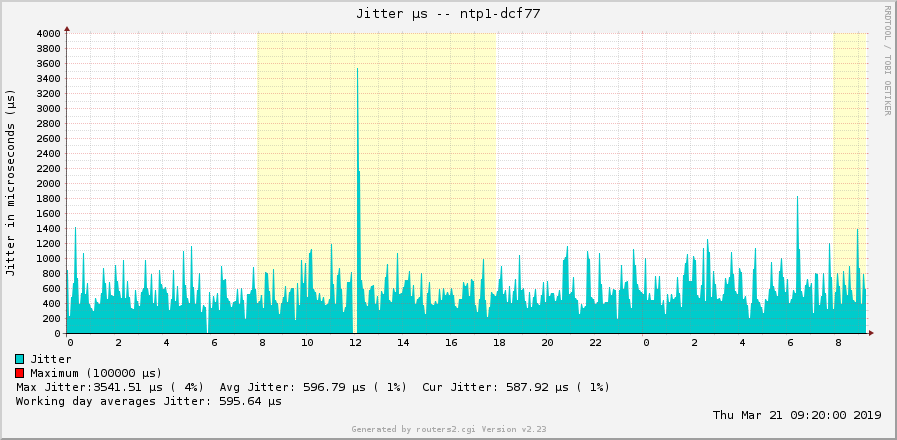
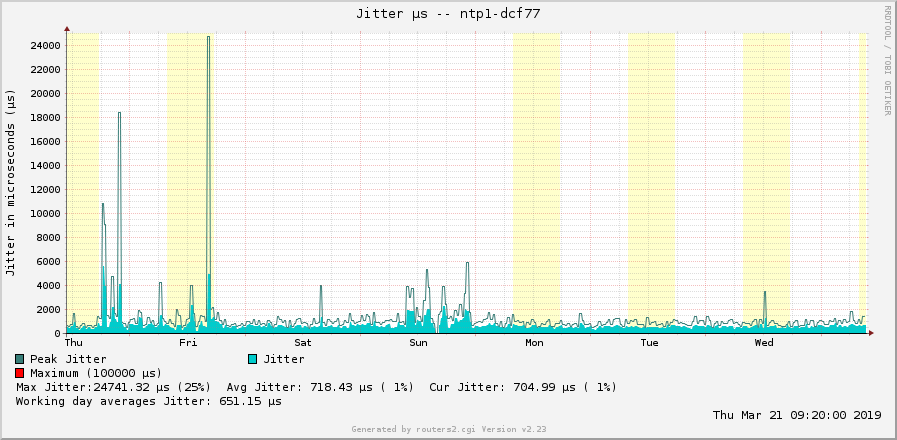


MRTG draws and calculates the peak only for positive values. Hence this black line in the offset graphs only appears in the upper half. Furthermore, my old ntpq package on my monitoring server only gives me three positions after the decimal point. Hence the offset graph from the GPS based NTP server looks quite discrete since the values are only swapping between -2, -1, 0, +1, +2, without any intermediate states. Running on a newer version of ntpq there would be more detailed.
Reach
Reach: “This is an 8-bit left shift octal value that shows the success and failure rate of communicating with the remote server. Success means the bit is set, failure means the bit is not set. 377 is the highest value.”
Note that monitoring this value is NOT accurate due to the fact that this reach field is an 8 bit shift register, represented as octal values to the user. Refer to some more detailed explanations on this such as here: Understanding NTP Reachability Statistics. In fact, you can have *lower* values just after a *higher* value even though your error is some minutes away. For example, having a single error (one 0), which is shifted towards the left of the buffer, results in octal values of: 376, 375, 373, 367, 357, 337, 277, 177, 377. That is: the second to last value of 177 is way below the very last value of 377, though it’s quite good since the last 6 queries succeeded. However, for some reason, I am mostly seeing 376 followed by a 377. Don’t know why.
Anyway, it gives a good overview at a glance of whether your NTP server’s reference clock is reachable or not. That’s why I am monitoring it. For my DCF77 based NTP server there is only one reach to look at (the one from the “GENERIC(0)” DCF77 module), while the GPS based NTP server has two values: one from the PPS(0) that gives the high accurate ticks and one from the SHM(0) which is the gpsd driver:
|
1 2 3 4 5 6 |
weberjoh@vm01-mrtg:~$ ntpq -c peers ntp1.weberlab.de | grep 'GENERIC(0)' | awk '{print $7}' && echo 0 377 0 weberjoh@vm01-mrtg:~$ ntpq -c peers ntp2.weberlab.de | grep 'PPS(0)' | awk '{print $7}' && ntpq -c peers ntp2.weberlab.de | grep 'SHM(0)' | awk '{print $7}' 377 377 |
I am using two MRTG Targets since I have two NTP servers, ntp1 with DCF77 and ntp2 with GPS/PPS. In the end I am additionally using a summary graph to display all reach lines in one single diagram:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
############################################################### ########################### Reach ############################# ############################################################### Target[ntp1-dcf77-reach]: `ntpq -c peers ntp1.weberlab.de | grep 'GENERIC(0)' | awk '{print $7}' && echo 0` MaxBytes[ntp1-dcf77-reach]: 377 Title[ntp1-dcf77-reach]: Reach -- ntp1-dcf77 Options[ntp1-dcf77-reach]: gauge integer YLegend[ntp1-dcf77-reach]: Reach 0 - 377 Legend1[ntp1-dcf77-reach]: Reach Legend3[ntp1-dcf77-reach]: Peak Reach LegendI[ntp1-dcf77-reach]: Reach: ShortLegend[ntp1-dcf77-reach]: routers.cgi*Options[ntp1-dcf77-reach]: fixunit nototal noo routers.cgi*ShortDesc[ntp1-dcf77-reach]: Reach ntp1-dcf77 routers.cgi*Icon[ntp1-dcf77-reach]: tick-sm.gif routers.cgi*Graph[ntp1-dcf77-reach]: ntp-reach Target[ntp2-gps-reach]: `ntpq -c peers ntp2.weberlab.de | grep 'PPS(0)' | awk '{print $7}' && ntpq -c peers ntp2.weberlab.de | grep 'SHM(0)' | awk '{print $7}'` MaxBytes[ntp2-gps-reach]: 377 Title[ntp2-gps-reach]: Reach -- ntp2-gps Options[ntp2-gps-reach]: gauge integer YLegend[ntp2-gps-reach]: Reach 0 - 377 Legend1[ntp2-gps-reach]: Reach PPS Legend2[ntp2-gps-reach]: Reach GPS Legend3[ntp2-gps-reach]: Peak Reach PPS Legend4[ntp2-gps-reach]: Peak Reach GPS LegendI[ntp2-gps-reach]: Reach PPS: LegendO[ntp2-gps-reach]: Reach GPS: ShortLegend[ntp2-gps-reach]: routers.cgi*Options[ntp2-gps-reach]: fixunit nototal routers.cgi*ShortDesc[ntp2-gps-reach]: Reach ntp2-gps routers.cgi*Icon[ntp2-gps-reach]: tick-sm.gif routers.cgi*Graph[ntp2-gps-reach]: ntp-reach routers.cgi*Title[ntp-reach]: NTP Reach Summary routers.cgi*ShortDesc[ntp-reach]: Reach Summary routers.cgi*Options[ntp-reach]: nototal routers.cgi*Icon[ntp-reach]: tick-sm.gif routers.cgi*InSummary[ntp-reach]: yes |
Here are some sample graphs in the “weekly” version:

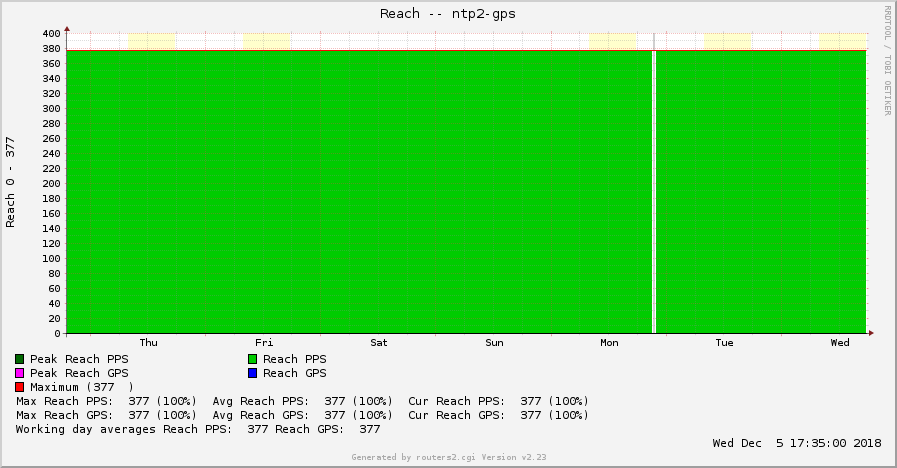

And here’s one example of this reach graph in which I discovered a DCF77 outage in Germany on my DCF77 Raspberry Pi (and another graph from my Meinberg LANTIME, which I am covering in another blog post):
Today (2018-12-04) from 2:45 to 6:45am UTC+1 the #DCF77 signal was lost on both of my NTP servers (Meinberg & RaspberryPi, residing on different physical locations). Don't know why. Any ideas? @MeinbergSync @shad0whunter @CharlyKuehnast pic.twitter.com/zryslcG4qt
— Johannes Weber 🎸 (@webernetz) December 4, 2018
Traffic
Finally, the iostats “display network and reference clock I/O statistics”, standard NTP query program. Those “received packets” and “packets sent” values do not only list the NTP client/server packets from the network but also the internal packets that NTP uses to query the reference clock driver. Hence those packet rates do not directly point to the number of NTP clients that are using this particular server, but at least give some basic thoughts about it. However, for example, my DCF77 receiver has quite different packet rates when it’s working compared to the GPS receiver, so it’s hard to compare them directly.
Originally I wanted to get the counters to my monitoring server in the same way as the above-mentioned jitter/offset values, but my fairly old ntp package on my MRTG server wasn’t aware of those received/send packets counters. Hence I used method number two (as explained in the beginning) in which I extended the SNMP daemon on the NTP server to run some scripts that I can then query from the monitoring server via SNMP. Note that you should use method one for this! My SNMP thing is just a workaround.
|
1 2 3 4 |
pi@ntp2-gps:~ $ ntpq -c iostats | grep 'received packets' | awk '{print $3}' 735379 pi@ntp2-gps:~ $ ntpq -c iostats | grep 'packets sent' | awk '{print $3}' 671111 |
That is: On the NTP server itself I added the following two lines to the sudo nano /etc/snmp/snmpd.conf file at the “EXTENDING THE AGENT” section:
|
1 2 |
extend-sh ntprx ntpq -c iostats | grep 'received packets' | awk '{print $3}' extend-sh ntptx ntpq -c iostats | grep 'packets sent' | awk '{print $3}' |
while I am using this MRTG Target querying the appropriate OIDs via SNMP:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
############################################################### ########################## Traffic ############################ ############################################################### #Note that this graph shows packets rather than bytes! #That is: MaxByte set to max 10.000 packets per second. That should fit. ;) Target[ntp2-gps-iostats]: 1.3.6.1.4.1.8072.1.3.2.3.1.1.5.110.116.112.114.120&1.3.6.1.4.1.8072.1.3.2.3.1.1.5.110.116.112.116.120:THISISTHEKEY@ntp2.weberlab.de::11:::2 MaxBytes[ntp2-gps-iostats]: 10000 Title[ntp2-gps-iostats]: Traffic Analysis ntpd in Packets -- ntp2-gps YLegend[ntp2-gps-iostats]: packets per second ShortLegend[ntp2-gps-iostats]: packets/s routers.cgi*Options[ntp2-gps-iostats]: nomax routers.cgi*GraphStyle[ntp2-gps-iostats]: mirror routers.cgi*ShortDesc[ntp2-gps-iostats]: Traffic ntp2-gps |
This gives you graphs like this. Note the third one from an NTP server within the NTP Pool Project that peaks when it is used:
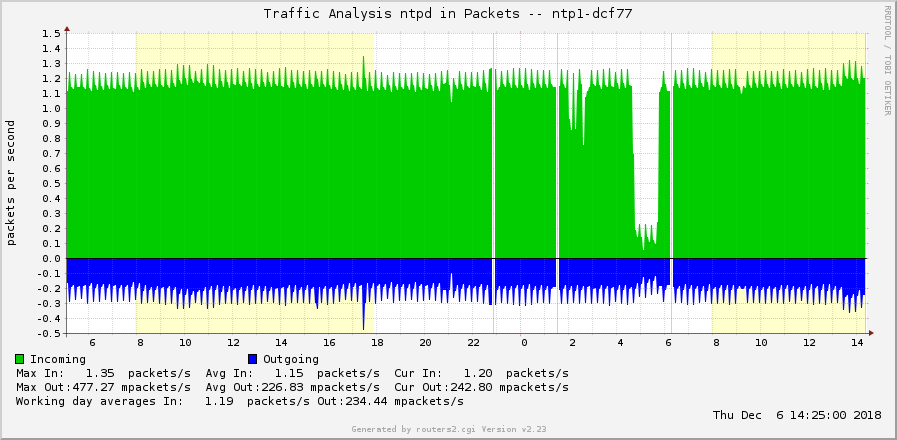

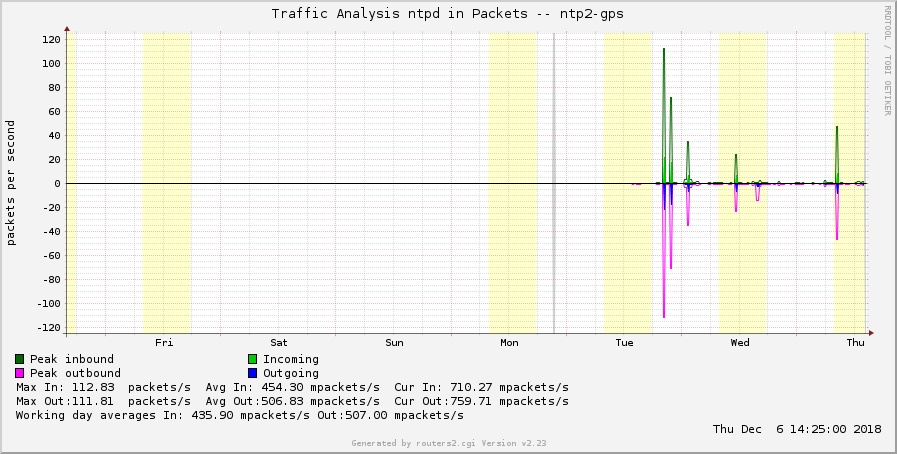

What’s missing? -> Alerting!
Please note that I have not yet used any kind of automatic alerting function. If you’re running your own stratum 1 NTP servers you should get informed in case of a hardware or software error, or just in case your antenna is faulty. Your reach should always be 377, while the offset should be lower than 1 ms all the time, and so on. Please use your own setups to keep track of those values.
That’s it for now. Happy monitoring! ;)
Featured image “Robert Scoble, Coachella 2013 — Indio, CA” by Thomas Hawk is licensed under CC BY-NC 2.0.
Just to share with you my work about ntp monitoring https://github.com/dmachard/ntpd-monitoring
Thanks for your blog, it’s great :)
Denis
Nice. Thanks for that, Denis!
Nice article!
I think you can save yourself a grep or two by doing things like:
ntpq -c ‘rv 0 clk_jitter’ ntp.example.nl | sed s/.*jitter.// | sed s/,//
Or even shorter:
ntpq -c ‘rv 0 sys_jitter’ ntp.example.nl | sed s/sys_jitter.//
Help, How can I monitor why reach = 1
remote refid st t when poll reach delay offset jitter===================================================================
171.10.32.20 171.21.34.132 5 u 5 64 1 0.561 431.966 269.791
171.10.32.17 171.21.34.132 5 u 4 64 1 0.585 437.766 282.035
127.127.1.0 .LOCL. 5 l 37 64 7 0.000 0.000 0.000
170.10.32.52 171.10.32.20 6 u 4 64 1 0.146 421.169 279.228
Uh sorry, now idea. It looks like your servers are stratum 5. Maybe they don’t have a reliable NTP connection? Most servers in the NTP pool or the like are stratum 1, 2, or 3. You could do a packet capture. Or test other servers. Or test the same servers from other clients.
Uh yes. Nice. Thanks for that. I wasn’t aware that I can request a single variable with “-c …”.
Any guides out there using some of the more modern tools for setting up some nice graphs of offset and jitter? I’m tempted to use your old tools because you wrote a detailed guide that walks Linux newbies through every step.
I use Grafana / Prometheus. Searching for ‘grafana ntp’ on the internet will get you some examples.
You are seeing 376 and 377 in your reachability register because of the order of events. Suppose the register value is 377 when ntpd sends its poll packet. At that moment it shifts a 0 into the least-significant bit of the reachability register. The 0 means ntpd hasn’t yet received a reply to the last poll. If you sample at this point, you’ll see 376. This tells you there were replies to the previous 7 polls, but not yet to the last poll. Then, when the reply is received, the least-significant bit is changed to 1. If you sample at this point, you’ll see 377.